
Knowledge graphs in Natural Language Processing @ ACL 2019
Published:
Hello, ACL 2019 has just finished and I attended the whole week of the conference talks, tutorials, and workshops in beautiful Florence! In this post I would like to recap how knowledge graphs slowly but firmly integrate into the NLP community ![]()

ACL 2019 was enormous - 2900 submissions, 660 accepted papers, more than 3000 registered attendees, and four workshops with about 400 attendees (well, workshops are bigger than some international CS conferences). For instance, Mihail Eric compiled a great post on general ACL trends. In addition to hot topics such as BERTology, transformers, and machine translation, new trends show up as well, e.g., adversarial learning, natural language generation and knowledge graphs (KGs). I am personally very excited to see how much traction KGs acquire at top AI venues: about 30 papers out of 660 which is a good 5% share for such a huge event (well, hasn’t ACL always been a good place for symbolic AI folks? ![]() ) So I’d like to outline some major application domains where KGs were most represented and describe a bunch of very promising papers presented throughout the week. Due to the size of the conference I most probably missed something so let me know what to add to the list.
) So I’d like to outline some major application domains where KGs were most represented and describe a bunch of very promising papers presented throughout the week. Due to the size of the conference I most probably missed something so let me know what to add to the list.
Dialogue Systems over Knowledge Graphs
Dialogue systems are traditionally classified into goal-oriented and chit-chat agents. Goal-oriented ones help a user to accomplish a certain task like booking a table in a restaurant or assisting a driver in the in-car scenarios (read my previous post if you’d like to get familiarized with a typical KG-based dialogue system). Chit-chat agents are about smalltalk, being interactive, entertaining and engaging. You probably heard about recent Deep Learning achievements in building end-to-end conversational agents without particular pipelines, especially chit-chat agents. Nevertheless, it gets more and more visible that both types of agents have to possess some knowledge, i.e., domain knowledge for goal-oriented agents and more of commonsense knowledge for chit-chat agents.
- The anticipation of such a technology can’t be expressed clearer than by the ACL president Ming Zhou himself - in his welcome speech he made an emphasis on importance of incorporating knowledge graphs, reasoning, and context into dialogue systems. I would also add that KGs are able to improve the explainability of agent’s answers. Therefore, if the president talks dialogue systems over KGs, there should be some work done in this field, right?

- More details were discussed at the NLP for Conversational AI workshop where Yejin Choi from the University of Washington presented an approach for integrating knowledge-seeded commonsense reasoning in dialogues (technical details are below in this text as well).
Ruhi Sarikaya from Amazon confirmed that Alexa still has to partly perform in the pipeline mode with knowledge extraction from structured sources (graphs, for instance).
Jianfeng Gao from MS Research explained how Xiaoice has to utilize structured information for user engagement (Xiaoice still holds a record for the longest conversation-step sequence for a chatbot).
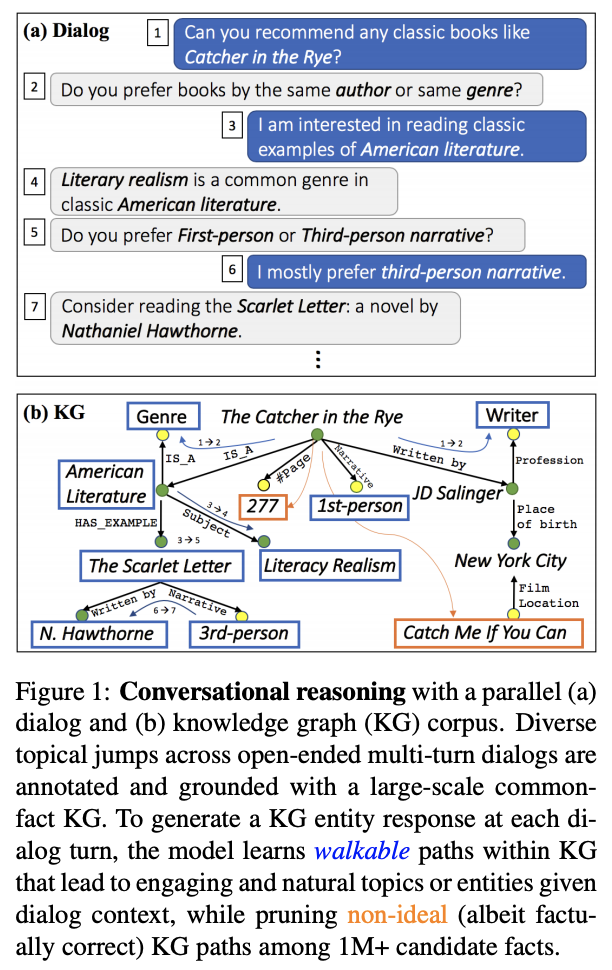
![]() Moon et al., 2019 from Facebook AI presented OpenDialKG - a new Open-Ended Dialogue - Knowledge Graph parallel corpus with 15K annotated dialogues, 91K turns which are grounded to the Freebase subset of more than 1M triples, 100K entities and 1358 relations. That’s a great step towards building KG-grounded conversational systems, and I hope Facebook example will encourage others! Moreover, the authors presented a novel DialKG Walk architecture that utilizes knowledge graphs in an E2E manner with an attention-based graph path decoder.
Moon et al., 2019 from Facebook AI presented OpenDialKG - a new Open-Ended Dialogue - Knowledge Graph parallel corpus with 15K annotated dialogues, 91K turns which are grounded to the Freebase subset of more than 1M triples, 100K entities and 1358 relations. That’s a great step towards building KG-grounded conversational systems, and I hope Facebook example will encourage others! Moreover, the authors presented a novel DialKG Walk architecture that utilizes knowledge graphs in an E2E manner with an attention-based graph path decoder.
My only concern is the selected graph - Freebase - is officially dead since 2014 and not supported for a long time, maybe it’s time for the community to switch to Wikidata? :thinking_face:
Natural Language Generation of Knowledge Graph facts
Generating coherent natural language utterances, e.g., from structured data, is a hot emerging topic as well. While purely neural E2E NLG models try to solve a problem of generating very boring text, NLG from structured data is challenging in terms of expressing the inherent structure in natural language. Knowledge graphs are hard to verbalize, too. For instance, you can generate a bunch of different sentences from a triple (Berlin, capitalOf, Germany), but when you have a set of connected triples like (Berlin, capitalOf, Germany) . (World_Cup_2006, hostedBy, Germany) which option is more valid: “Berlin is the capital of Germany which hosted the World Cup 2006” or “Berlin is the capital of the country where World Cup 2006 took place”?
Surprisingly, ACL could offer quite a lot for verbalizing triples in KGs. First, I’d like to mention the workshop on storytelling organized by IBM Research which presented numerous challenges and possible ways towards solving the triples verbalization problem, be sure to check the slides!
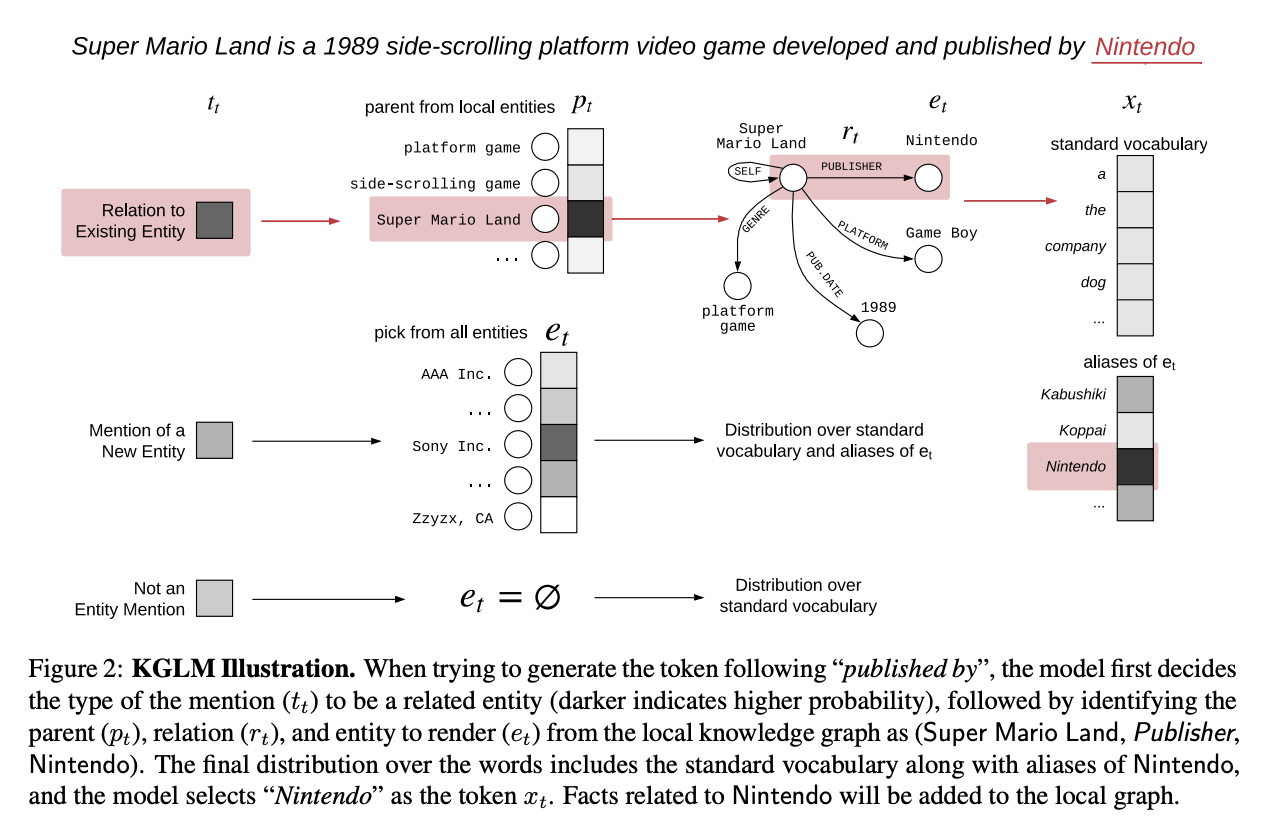
![]() A great paper and poster presentation by Logan et al. proposes to use language models like OpenAI GPT in conjunction with knowledge graph embeddings. The authors also introduced a new dataset, Linked WikiText-2, which training part consists of more than 41K entities and 1.5K relations annotated with Wikidata (yeah!).
A great paper and poster presentation by Logan et al. proposes to use language models like OpenAI GPT in conjunction with knowledge graph embeddings. The authors also introduced a new dataset, Linked WikiText-2, which training part consists of more than 41K entities and 1.5K relations annotated with Wikidata (yeah!).
Not from ACL 2019 but a very relevant work from the recent NAACL 2019, Moryossef et al. proposed Chimera - a two-fold model for NLG over triples. At first, given a set of triples, they generate text plans as graphs which retain compositionality of a given triples, rank them, and finally run a typical Neural Machine Translation (NMT) system with a copy mechanism to generate text sentences. The evaluation is based on the WebNLG dataset which also uses Wikidata entity and predicate IDs!
Complex Question Answering over Knowledge Graphs
Question answering as a reading comprehension task is one of the most popular benchmarks to track the progress of huge models like BERT. “Question answering over knowledge graphs (KGQA) aims to provide the users with an interface to ask questions in natural language, using their own terminology, to which they receive a concise answer generated by querying the KG.” (I’m citing a comprehensive study on KGQA recently published by my colleagues - here is the link Charkaborty et al., 2019). In the QA task, KGs provide a user with explainable results (actually, a graph pattern which can(or not) be found in a target graph). Moreover, they can perform sophisticated reasoning which reading comprehension systems are not yet able to achieve. ACL 2019 brought lots of state-of-the-art research you’d want to check out:
Saha et al. work on Complex Sequential Question Answering (CSQA) dataset (with Wikidata IDs ![]() ) which at the moment comprises the most difficult questions over KGs including aggregations (“Which people are the patron saint of around the same number of occupations as Hildegard of Bingen?”), verifications (“Is that administrative territory sister town of Samatice and Shamsi, Iran?”) and even more organized as a dialogue with coreference resolution over entities and relations. Approaches trained on simple questions without memory exhibit pretty poor performance, right now it seems that you’ll need some sort of a formal language or grammar to perform logical actions and aggregations. The authors of this paper introduce a grammar of several actions, e.g., set intersection, lookup in knowledge graph embeddings, etc, that is utilized by reinforcement learning to deduce a logical program able to answer those complex questions in the dialogue environment.
) which at the moment comprises the most difficult questions over KGs including aggregations (“Which people are the patron saint of around the same number of occupations as Hildegard of Bingen?”), verifications (“Is that administrative territory sister town of Samatice and Shamsi, Iran?”) and even more organized as a dialogue with coreference resolution over entities and relations. Approaches trained on simple questions without memory exhibit pretty poor performance, right now it seems that you’ll need some sort of a formal language or grammar to perform logical actions and aggregations. The authors of this paper introduce a grammar of several actions, e.g., set intersection, lookup in knowledge graph embeddings, etc, that is utilized by reinforcement learning to deduce a logical program able to answer those complex questions in the dialogue environment.

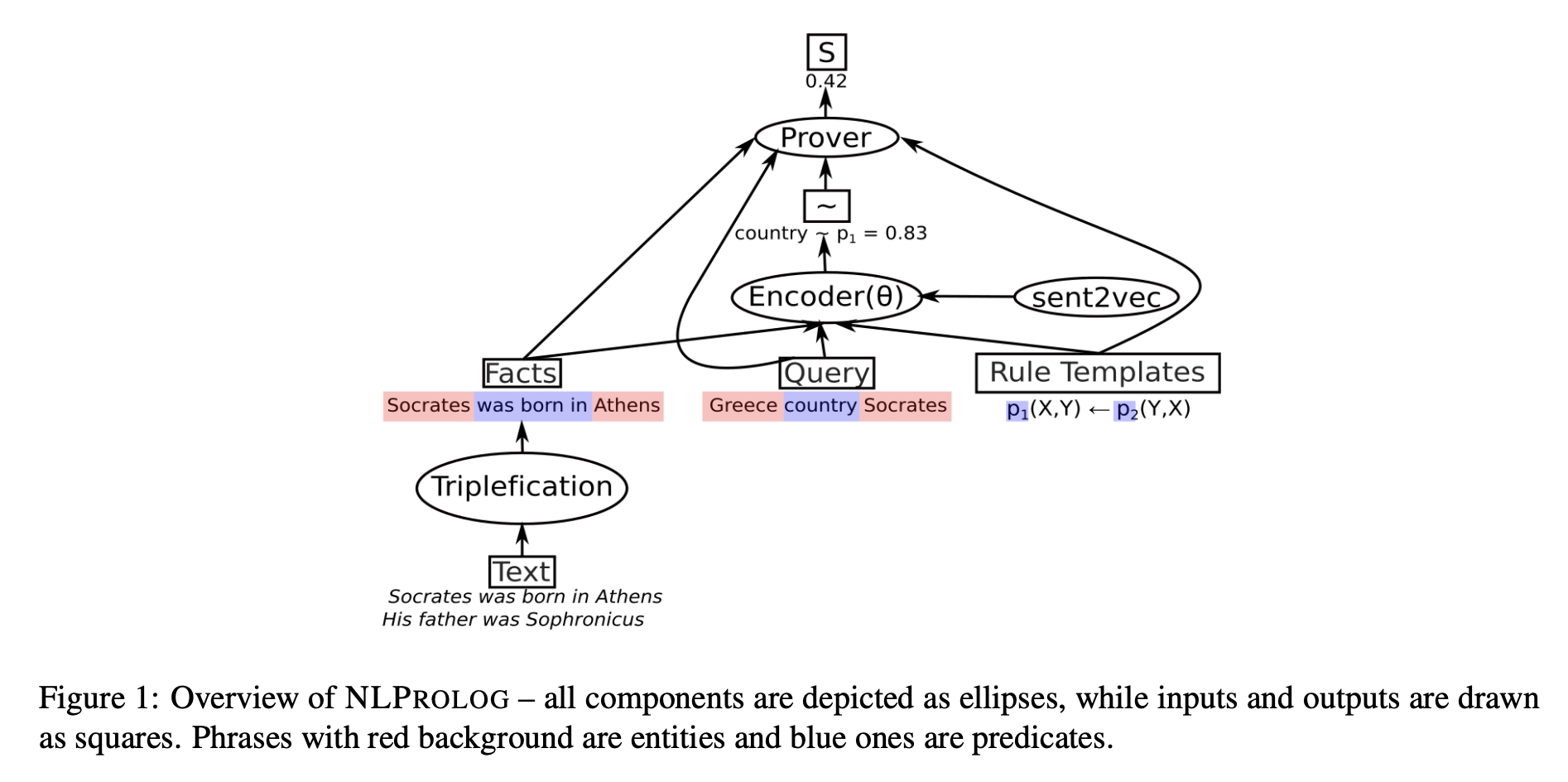
![]() Weber et al continue to work on Neural Prolog - a differentiable logic approach that combines a symbolic reasoning and a rule-learning method over sentence embeddings, can be applied directly to natural language text without the need of converting them to a logical form, and uses a Prolog-style inference to answer logical queries. So that, on one hand the framework is based on fuzzy logic (which is my guilty pleasure
Weber et al continue to work on Neural Prolog - a differentiable logic approach that combines a symbolic reasoning and a rule-learning method over sentence embeddings, can be applied directly to natural language text without the need of converting them to a logical form, and uses a Prolog-style inference to answer logical queries. So that, on one hand the framework is based on fuzzy logic (which is my guilty pleasure ![]() ) and pre-trained sentence embedding models. It seems to me that neural logic approaches are quite underestimated in the community, I’d expect more traction in this domain when research will start a battle for real explainability as both this and the above papers present a very well grounded and interpretable mechanisms how they inferred a particular answer.
) and pre-trained sentence embedding models. It seems to me that neural logic approaches are quite underestimated in the community, I’d expect more traction in this domain when research will start a battle for real explainability as both this and the above papers present a very well grounded and interpretable mechanisms how they inferred a particular answer.
Tackling simpler KGQA datasets, Xiong et al. propose an approach for QA over incomplete knowledge graphs where one would need to perform some link prediction, and Sydorova et al. achieved good results on the TextKBQA task where you have two knowledge sources - a graph and a text paragraph. Another approach enriching BERT-style reading comprehension model with KGs (WordNet and NELL in this case) is by Yang et al.. As of March 2019 their KT-NET outperformed purely MRC systems on SQuAD 1.1 and ReCoRD which confirms it is a promising approach to study.
Reading comprehension-based QA systems are still on fire as they got several sections of oral presentations and poster sessions dedicated just for them so I’m pretty sure there will be detailed reports on that field as well. In brief, new datasets like WikiHop or HotpotQA target multi-hop QA over entire Wikipedia articles where you need to combine knowledge from several articles to answer a question. CommonsenseQA consists of real questions from search engine logs so a system would need some sort of a commonsense reasoning. In order to distinguish sense-making cases from complete nonsense you’ll want to employ adversarial training and there were papers from Zhu et al. and Wu et al. which prove adversarial training is effective. Lastly, to overcome often small training datasets Alberti et al. introduce a paraphrasing data augmentation schema for questions where they were able to generate whopping ![]() 50M
50M ![]() additional questions to train their system on and achieved +2 to +3 F1 increase.
additional questions to train their system on and achieved +2 to +3 F1 increase.
NER and Relation Linking over KGs
The Information Extraction track at ACL 2019 was one of the most popular and attended! KGs show real benefits in Named Entity Recognition, Entity Linking, Relation Extraction, and Relation Linking. I was particularly interested in neural approaches that allow to build knowledge graphs from text sources. Lots of new datasets (with Wikidata IDs ![]() ) and approaches have been introduced.
) and approaches have been introduced.
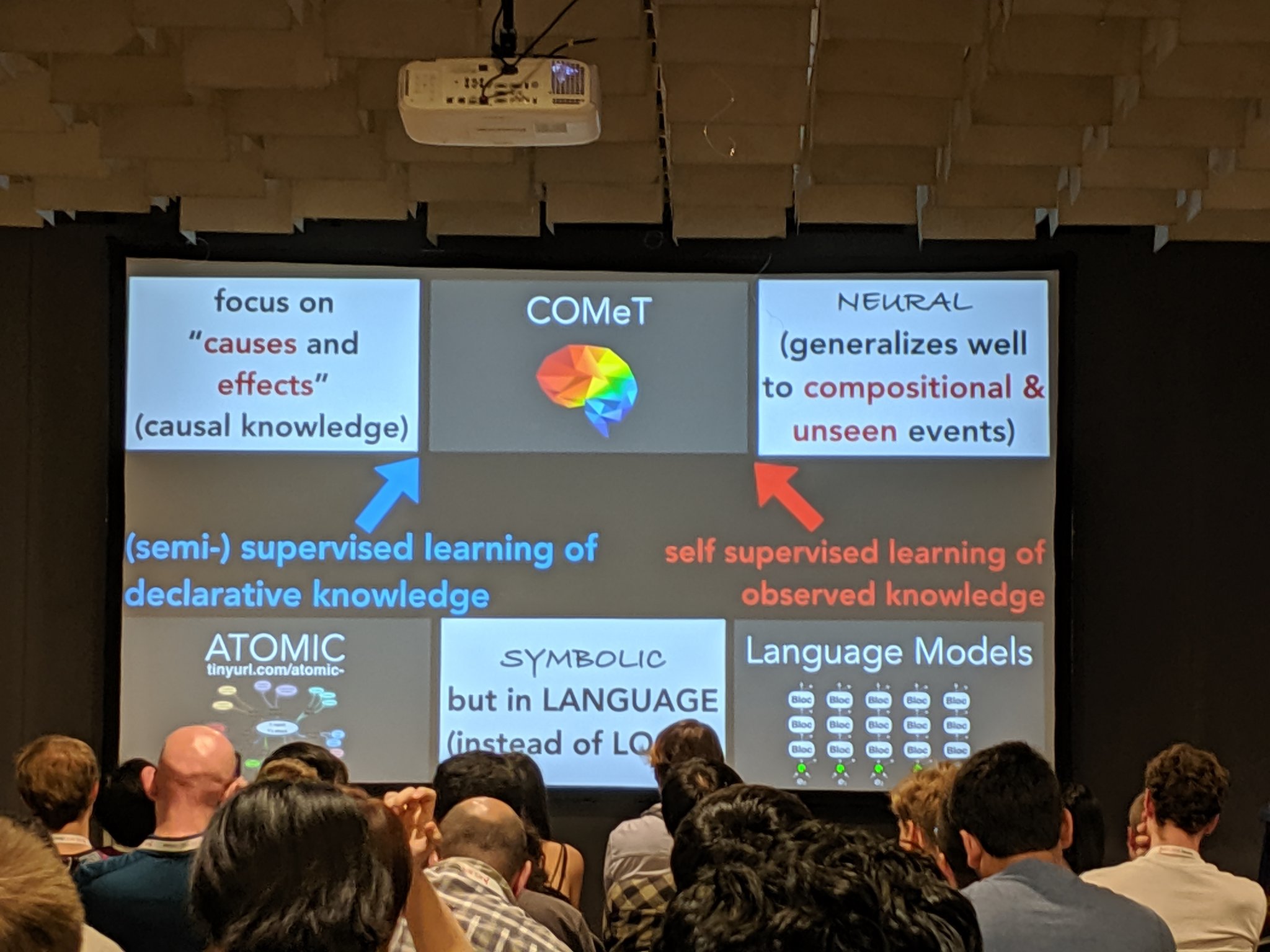
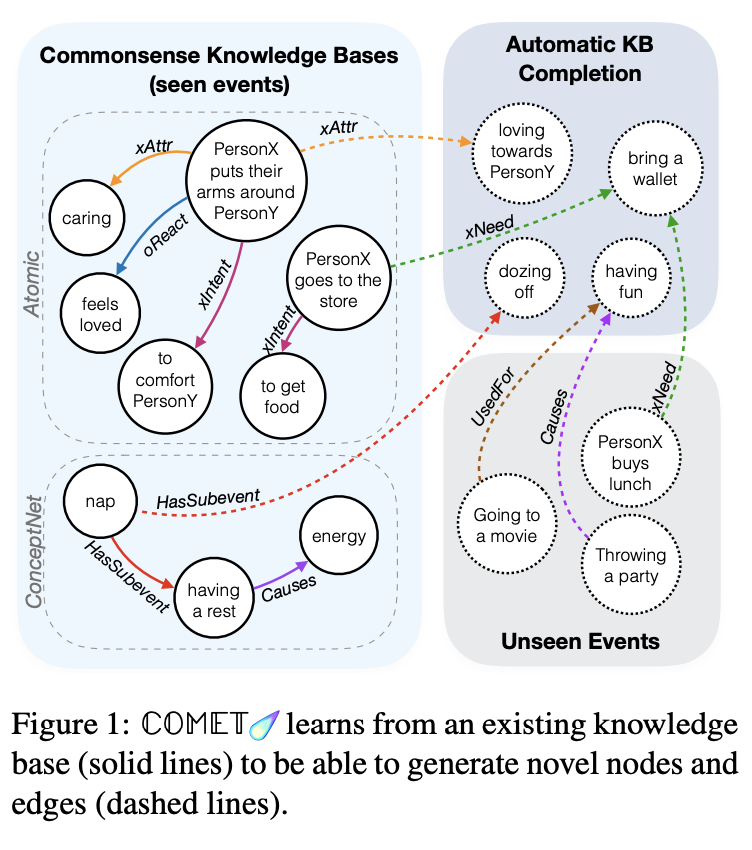
![]() One of my Top-3 favorite papers at the conference by Bosselut et al. introduces COMET - an architecture for commonsense transformers - where language model such as GPT-2 is combined with a seed knowledge graph like ATOMIC. Feeding COMET with seed tuples from a graph allows to learn its structure and relations. On the other hand, a language model is shaped with the graph representation in order to generate new nodes and edges and add them to the seed graph. Even cooler is that you can have a graph expressed as tuples of natural text like
One of my Top-3 favorite papers at the conference by Bosselut et al. introduces COMET - an architecture for commonsense transformers - where language model such as GPT-2 is combined with a seed knowledge graph like ATOMIC. Feeding COMET with seed tuples from a graph allows to learn its structure and relations. On the other hand, a language model is shaped with the graph representation in order to generate new nodes and edges and add them to the seed graph. Even cooler is that you can have a graph expressed as tuples of natural text like (take a nap, CAUSES, have energy). It would be very interesting to try out this architecture on smth as large as Wikidata.
New datasets and baseline models for relation extraction - and it’s very encouraging that they are based on Wikidata entities and predicates. Yao and Ye et al. propose a huge DocRED dataset which consists of 6 entity types, 96 relations, 2.5M entities (no WD IDs), 828K sentences in 102K documents. Trisedya et al. propose a WIKI dataset of 255K text-triple pairs, 280K entities, and 158 predicates which has a task of building a knowledge graph out of a given natural language sentence as well as a baseline model for this dataset. Moreover, Chen et al. introduce a dataset for relation similarity which consists of 426K triples, 112K entities, 188 relations.
Going more into information extraction, Zhu et al. show impressive results utilizing graph attention nets for relation linking. They model a composition of entities and relations in a sentence as a graph and using fancy GNNs able to identify multi-hop relations. SOTA performance with a significant margin!
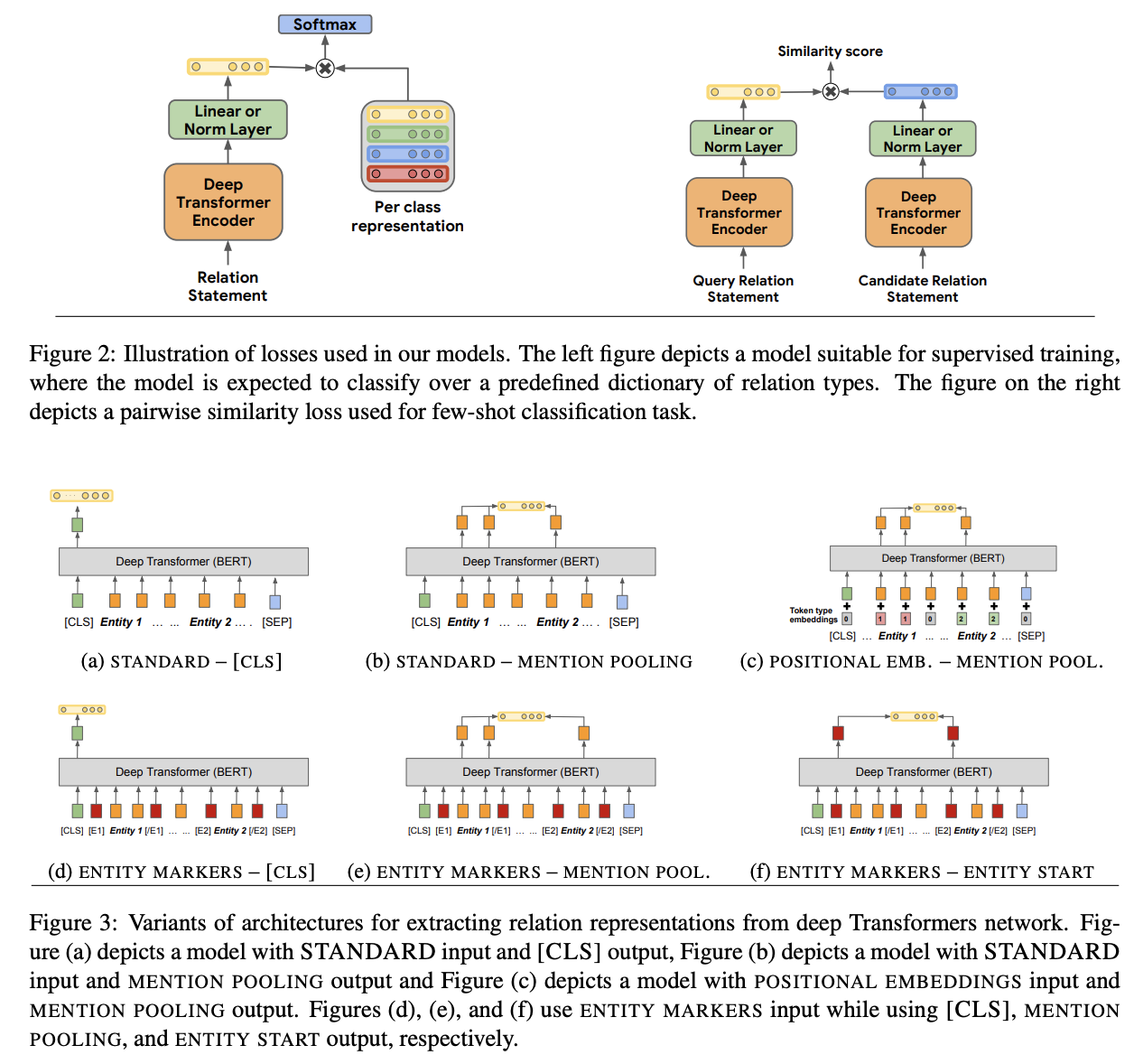
A work of Soares et al. describes a new approach for relation learning - pre-train a huge model like BERT and pass sentences through its encoder to obtain an abstract notion of a relation, and then fine-tune on a certain schema like Wikidata, TACRED, or DBpedia to get an actual predicate with a corresponding ID. It does make sense - usually KG-based IE approaches are tailored for a specific ontology, so when you have many tasks - you have many ontologies, too. Here the authors detach a relation from any schema and allow to extract even quite generic relations that you might want to include into your own schema. The approach exhibits a substantial accuracy increase especially in zero- and few-shots tasks - so that you can employ it in scenarios where training data is pretty limited.
For entity linking, Logeswaran et al. propose to use BERT-like pre-trained reading comprehension models in order to generalize to unseen entities in unseen domains. For that, they introduce a domain-adaptive pre-training (DAP) strategy, and a new task for zero-shot entity linking in unseen domains. Right now the dataset consists of Wikia articles, but I presume there shouldn’t be much trouble applying the framework to knowledge graphs that can contain multilingual labels and synonyms or well-defined domain-specific ontologies.
Hosseini et al. in their work study a problem of extracting a relations graph directly from the natural language text, and they achieve remarkable results on the evaluated datasets. A similar task is tackled by Shaw et al. where they apply graph nets (GNNs are admittedly quite on fire those days) to obtain logical forms with entities.
Wu et al. study relation representations in KGs and propose a Representation Adapter model that is able to generalize to unseed relations based on existing KG embeddings. The authors also tweak the SimpleQuestion (SQ) dataset into SimpleQuestions-Balance (SQB) where the distribution of seen vs unseen predicates in train/test splits gets, you name it, more balanced.
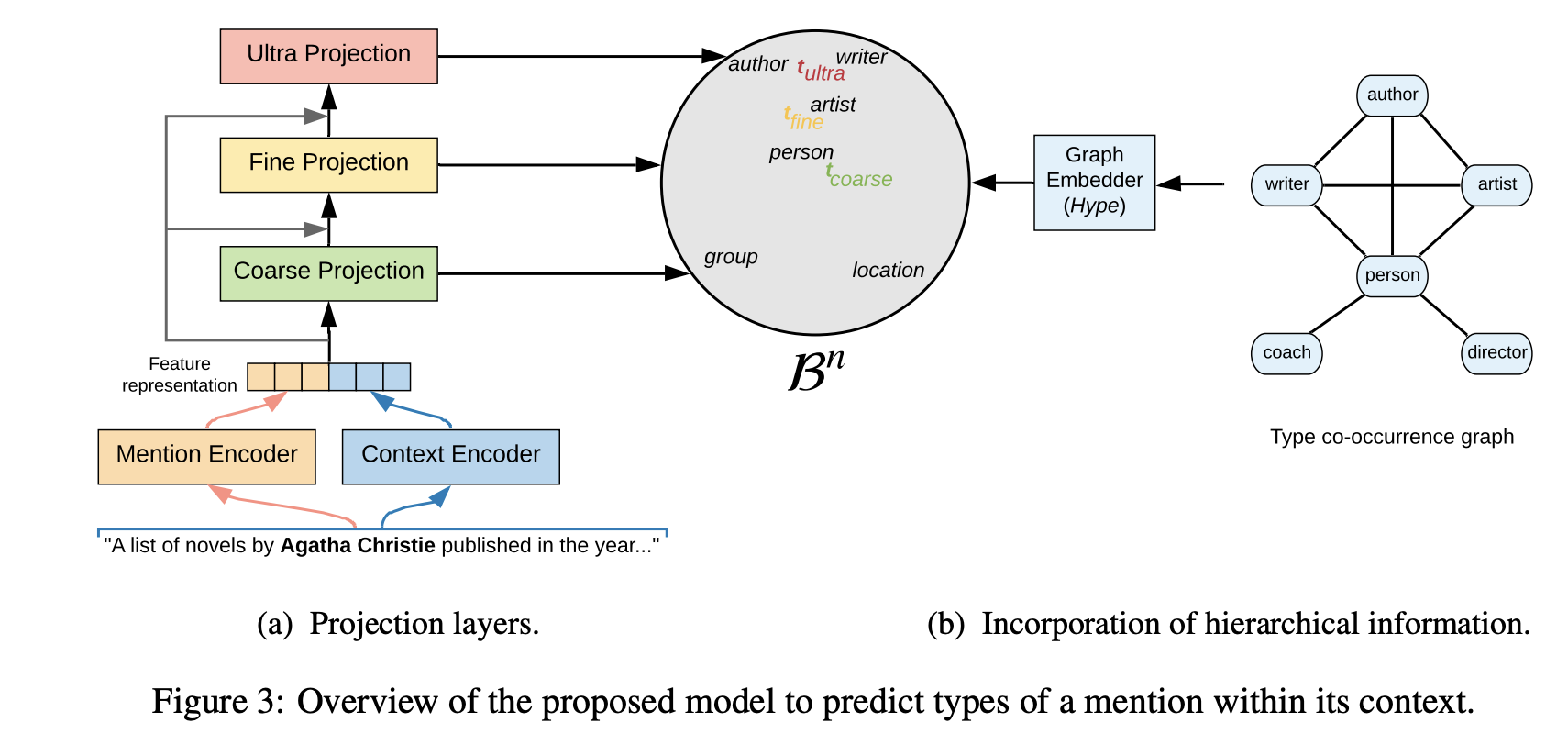
Talking about Named Entity Recognition (NER), I’d like to outline a work by Lopez et al. on “Fine-grained Entity Typing in Hyperbolic Space”. Using a flat list of possible entity types (that gets converted to a graph with subsequent graph nets representation) and entity mentions they build a hyperbolic embedding space able to infer the mention context and specialize an entity type to a good extent. For instance, given a sentence “A list of novels by Agatha Christie published in …”, Agatha Christie will be typed not only as a Human, but as a more fine-grained Writer class. Actually, the framework trained on UltraFine dataset can specialize up to three levels! On OntoNotes the results are on par with SOTA approaches.
KG Embeddings & Graph Representations
Maybe one would consider an NLP conference as not the best place to learn about graph representation learning, but look, there was a bunch of very insightful papers which try to encode knowledge graphs both structurally and semantically!
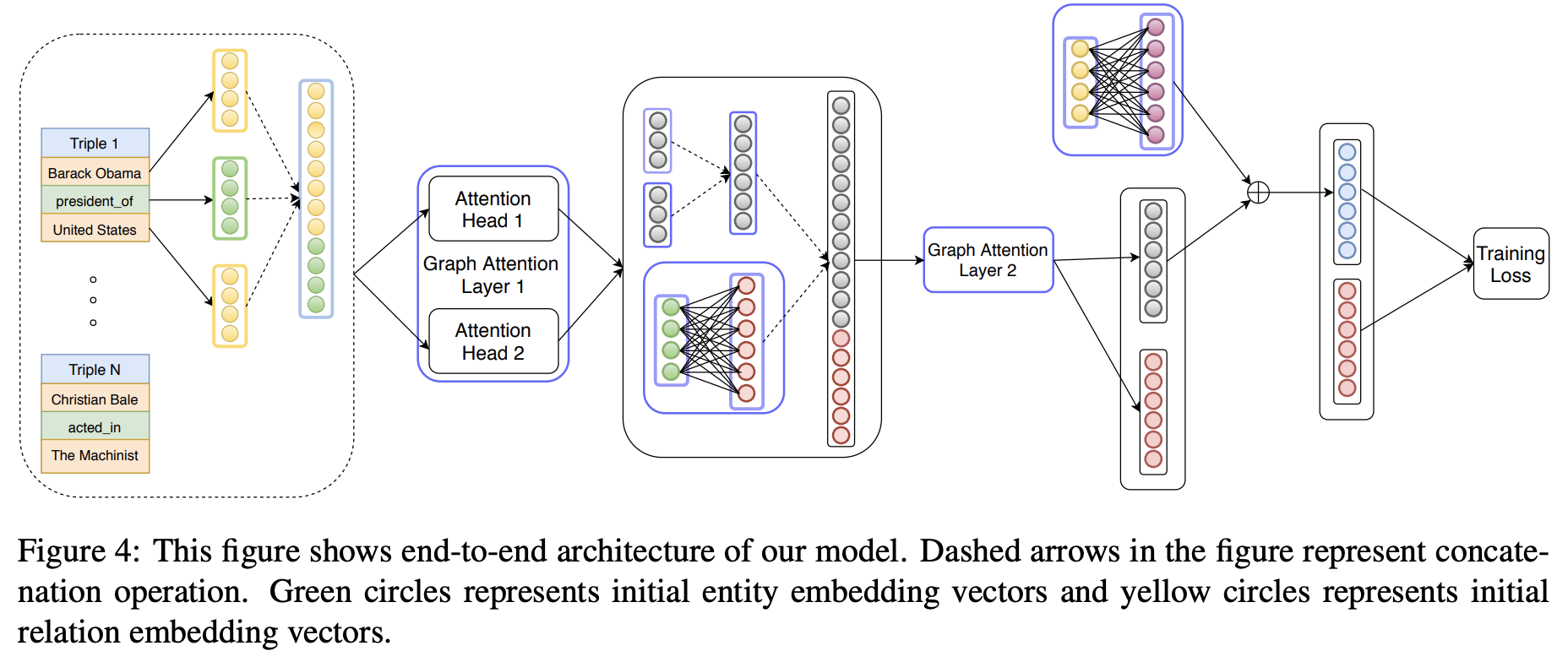
Nathani et al. introduce a knowledge graph embedding approach based on graph attention networks (GAT) that consider node and edge features in the attention mechanism. The authors employ a multi-head attention architecture and put a significant emphasis on learning relations representations. Benchmarking over four datasets (in addition to WN18RR and FB15k-237 authors took NELL-995 and Kinship) yields a significant increase in SOTA performance. Actually, this approach is quite better than the following one presented the same day at ACL :D
Bansal et al. propose A2N - a knowledge graph embedding technique with neighbourhood attention. Aggregating messages from the neighbourhood enables better representation of multi-hop relations which authors show in the evaluation. In the Relation Predication benchmarks A2N performs on par or better than ConvE. However, compared to the above approach in Hits@N and MRR A2N is somewhat inferior. I’d encourage authors to compare training times and memory consumption!
MATH ALERT ![]() A work by Xu and Li stands out a bit from the previous two as they employ dihedral groups for modeling relations in KG embeddings. Math in the paper is quite advanced (challenge yourself
A work by Xu and Li stands out a bit from the previous two as they employ dihedral groups for modeling relations in KG embeddings. Math in the paper is quite advanced (challenge yourself ![]() ), so in short - dihedral groups allow to model non-Abelian compositions of predicates, e.g.,
), so in short - dihedral groups allow to model non-Abelian compositions of predicates, e.g., parent_of o spouse_of != spouse_of o parent_of where o denotes matrix multiplication. Moreover, the approach enables to model symmetric and inverse relationships between predicates (like already in advanced OWL ontologies). While performance on traditional benchmarks is on par with ConvE as they consist of mostly Abelian compositions, the authors build a FAMILY dataset which heavily uses non-Abelian compositions. That is, the paper is definitely worth a look, but be ready for some math. END OF MATH ALERT
Kutuzov et al. describe a framework for building graph embeddings where instead of vector-based distance functions they optimize graph-based metrics (like shortest path) and plug in custom node similarity functions like Leacock-Chodorow. While inference speed is increased, the approach can’t utilize node features and edges features which is claimed to be a future work. Dear authors, we’ll anticipate ![]()
Stadelmeier and Pado introduce a context path model (CPM) aimed at providing an explainability layer on top of traditional KG embeddings approaches. The authors propose to use two optimization scores - correction score of a path and relevance score between a triple and a path, i.e., strength of the correctness signal.
Wang et al. in their work “On Evaluating Embedding Models for Knowledge Base Completion” state a recurring issue in the KG embeddings evaluations - are their predictions logically consistent? For instance, in graphs we might have rules like “Roger can’t be friends with David” (instance level) or “Humans can’t be made of Wood” (class level) which means that KG embeddings should take in into account and decrease a probability of such statements to appear. They find that right now most of KG embeddings models can assign a non-zero probability value to rather unrealistic triples.
Conclusions
Clearly, more and more folks get interested in applying knowledge graphs in various NLP domains. New datasets and tasks on KGs appear more often and this is cool! Oral talks have been fully recorded - check out the videos in the program. Illustrating pictures were taken from the respective papers, other photos were taken by me ![]()
See you at the next conference! ![]()
