Лекция 1
Введение в представление знаний
| Материалы | Ссылка |
|---|---|
| Видео | YouTube |
| Слайды | |
| Конспект | здесь |
| Домашнее задание | link |
Видео
Часть 1 - Введение
В этой лекции мы рассмотрим способ представления и хранения знаний, который стал стандартом де-факто в современных интеллектуальных системах. По сравнению с традиционными системами бизнес-правил, продукций или семантических сетей, отличительной особенностью графов знаний, является их логическая строгость, развитые возможности автоматического пополнения базы знаний, интеграция с хранилищами данных и масштабируемость на большие объемы информации, а также поддержка выполнения запросов подобно тому, как это делается в базах данных. Все это делает графы знаний очень удобным инструментом для работы со знаниями в сети Интернет.
Проблема
Прежде чем говорить о знаниях в сети Интернет, давайте вспомним, насколько быстро растет сеть. Тот факт, что 90% информации в этом мире было сгенерировано за два последних года уже никому не кажется удивительным, но давайте попробуем вглядеться в эти числа.
Перед нами годовая инфографика [0] Data never sleeps 6.0, иллюстрирующая производство информации и онлайн-поведение людей и разработанная с помощью платформы Domo, которая предоставляет инструменты для бизнес-аналитики и визуализации данных.
Как мы видим, темпы роста информации весьма и весьма внушительные. Только в США в среднем выкладывают в Интернет более 2,5 миллионов гигабайт данных каждую минуту. Но в контексте нашей лекции интересны даже не эти внушительные объемы информации, а их структура и всё более тесная взаимосвязь в данных. Для того, чтобы превратить разрозненную сеть веб-документов в самую большую в истории человечества коллекцию знаний, необходимо научиться извлекать эти знания и представлять их в форме, понятной человеку с одной стороны, но и подходящей для эффективной машинной обработки и анализа с другой.
Возможно, у вас уже возник вопрос, зачем мы подчеркиваем важность машиночитаемых и машинопонимаемых знаний? Ответ очень прост: чтобы автоматизировать рутинные процессы, которые отнимают у людей много времени, и упростить более сложные процессы путем анализа исходных данных и возможных результатов.
Теория
Современной формой представления и хранения знаний в сети являются графы знаний — структуры, состоящие из уникальных сущностей (узлов графа) и связей между ними (ребер графа). Сущностями могут быть как материальные вещи, так и абстрактные концепции. Например, “Университет ИТМО” как материальный концепт и “Университет” как собирательное описание всех университетов.
Связи (ребра графа) описывают отношения между сущностями и их атрибуты (также называемые свойствами). Например, “дата основания” - это атрибут для сущности “Университет ИТМО” и может содержать значение “26.03.1900”, тогда как для абстрактного концепта “Университет” атрибут “дата основания” может содержать “некоторую условную дату” и создать высказывание, что каждый университет имеет дату основания.
Таким образом, графы знаний позволяют моделировать как абстрактные логические высказывания и схемы, так и наполнять эти схемы конкретными объектами реального мира. Более того, графы знаний позволяют машинам производить рассуждения и выводить новые знания, ранее не описанные в графе. Формальная полуструктурированность и мощный логический аппарат отличают графы знаний от традиционных реляционных баз данных, которые являются структурированными, то есть обладают установленными связями и отношениями.
Исследование графов знаний стоит на стыке многих областей компьютерных наук: информационный поиск (information retrieval), позволяющий ускорить наполнение графа из различных источников; обработка естественных языков (natural language processing) и семантические технологии (semantic technologies), которые позволяют описывать и использовать при анализе смысл хранящихся знаний; системы управления базами данных (data management), обеспечивающие эффективное хранение графов; машинное обучение (machine learning), необходимое для анализа содержащихся в исходных данных знаний и генерации новых знаний; искусственный интеллект в целом (artificial intelligence) как общее теоретико-методологическое обобщение, изучающее возможности машинного интеллекта.
В этом курсе мы рассмотрим два основных способа представления графов знаний: в символьном и векторном видах. Символьное представление подразумевает запись фактов с помощью символов (например, RDF-триплетов), тогда как в векторном представлении сущности и предикаты проецируются в некоторое d-размерное пространство (embedding space). Нельзя сказать, что какое-то из этих представлений предпочтительнее другого: символьное представление крайне полезно в задаче интеграции данных, тогда как векторные представления часто используются в задачах машинного обучения. Первая часть этого курса сосредоточится на символьном представлении, вторая - на векторном.
Графы знаний в их современном представлении имеют более чем 10-летнюю историю развития. Вероятно, наиболее ценными являются графы знаний, специфические для отдельных предметных областей. Но мы для простоты понимания их сути рассмотрим графы общего назначения. Основы и концепция открытых для пользователей графов знаний были впервые реализованы в 2007 в базе знаний DBpedia [1], созданной в результате семантической обработки инфобоксов статей в Wikipedia [2].
Тогда как сам термин “граф знаний” ввела в обращение компания Google с ее Google Knowledge Graph [6]. Со временем в DBpedia добавилась подробная схема данных (онтология), географические данные и связи с другими графами. В настоящее время DBpedia считается одним из стандартов графов знаний и содержит более 6 миллиардов связанных фактов.
В 2008 году был разработан граф YAGO [3]. Его отличительная особенность в использовании семантического тезауруса WordNet [4] и очень детальной иерархии классов сущностей. В настоящее время YAGO содержит около 120 миллионов фактов.
В 2010 году была запущена система Never-Ending Language Learner (NELL) [5][NELL], которая “читает” веб-страницы и автоматически перемещается между ними, пытаясь выделять факты из текста веб-страниц в граф знаний. В настоящее время NELL содержит около 14.5 миллиардов фактов, включая два миллиона фактов, в правдивости которых NELL полностью уверен.
Запущенный в 2007 году граф знаний Freebase использует отличный от трех предыдущих графов подход к моделированию фактов. Вместо использования заранее созданных схем данных (онтологий) Freebase позволяет пользователям самим назначать категорию описываемой сущности, что напоминает скорее облако тэгов, чем дерево классов.
В 2014 году Freebase содержал около двух миллиардов фактов и был приобретен компанией Google а затем преобразован в Google Knowledge Graph [6], предоставляющий единообразные знания всем сервисам компании, от поиска и почты до голосовых помощников. Граф знаний Google значительно повысил интерес академического и бизнес-сообщества к задаче представления знаний, задав тренд на следующие годы.
Если DBpedia использует данные Wikipedia для наполнения графа, то разработанный и запущенный в 2012 году граф Wikidata [7] предназначен для хранения знаний, которые будут использованы уже в Wikipedia (чаще всего в виде заполнения инфобоксов и таблиц на странице) на многих доступных языках. Wikidata использует усовершенствованный подход к моделированию знаний, позволяющий более детально описывать сущности и отношения.
В настоящее время Wikidata содержит около 7 миллиардов фактов о более чем 50 миллионах сущностей. Большинство публикуемых в последнее время графов знаний старается использовать модель Wikidata или связывать свои сущности с имеющимися в Wikidata.
Доступные в Интернете графы знаний образуют облако связанных данных — Linked Open Data Cloud (LOD Cloud) [8], семантически объединяя опубликованные графы в одну гигантскую сеть. И если в 2007 году это облако состояло всего из 12 графов, то в 2018 оно выросло до 1234 графов в девяти разных доменах.
Часть 2. Сценарии использования графов знаний
Есть ли перспективы у графов знаний в индустрии? Авторитетное аналитическое бюро Gartner в 2020 году поставило графы знаний на восходящую дугу Hype Cycle в области технологий ИИ [9]. PwC в своем анализе рынка указали, что почти все крупнейшие мировые компании в той или иной мере занимаются построением и применением графов знаний [10] - от технологических гигантов Apple и Google до финансовых конгломератов. А это значит, что потребность в технологиях вокруг графов знаний и экспертов в этой области будет определенно расти. К числу таких технологий можно отнести СУБД для хранения графов и обработки запросов к ним, системы интеграции данных (например, из data lakes) в графы знаний, диалоговые системы на базе графов знаний, и системы бизнес-аналитики.
Рассмотрим различные сценарии использования графов знаний:
-
Пожалуй, самый массовый сценарий на данный момент — это обогащение результатов поиска Google с помощью Google Knowledge Graph. Например, при поиске человека общая информация о нем (при наличии в графе) выводится в отдельном инфобоксе. При поиске ресторанов выводится место, ожидаемая кухня и примерная цена ужина. В дополнение, поисковая система умеет отвечать на простые фактологические вопросы: когда родился определенный человек или где находится определенное место.
-
Ответы на более сложные вопросы, заданные на естественном языке, могут быть решены с помощью графов DBpedia или Wikidata, когда исходный запрос анализируется на предмет нахождения сущностей, описанных в графе. Полученная комбинация сущностей и связей образует множество подграфов, некоторые из которых могут содержать ответ. Эти подграфы переписываются в запрос к графу на формальном языке (например, на языке SPARQL, который мы рассмотрим позднее), и оценивается верность результата.
-
Интеграция данных из разнородных источников, особенно, когда источники представлены в разных форматах (CSV, XML, JSON, реляционные базы) и используют разные схемы данных. В этом случае графы знаний могут служить универсальным средством связи и интеграции этих источников (датасетов), как физически (когда данные и схема преобразуются в единое RDF представление), так и виртуально (когда данные остаются в исходных форматах, но граф знаний на уровне абстрактных схем интегрирует исходные датасеты). В таком случае запрос к графу знаний будет проанализирован и переписан для отправки в нативном формате конкретного источника. Другими словами, один SPARQL-запрос может быть разбит на подзапросы и переписан для исполнения в CSV, XML и JSON источниках.
-
Активно развивающаяся сейчас в сфере производства концепция Индустрии 4.0 [11] постулирует необходимость как можно большей автоматизации кибер-физических систем (например, роборука на сборочном производстве) и их взаимодействия между собой без участия человека. Для этого сценария использование графов знаний позволяет описывать технологический процесс производства конкретных изделий во взаимосвязи с конкретными технологическими операциями на конкретных машинах. Это, в свою очередь, позволяет роботам самостоятельно договариваться о необходимых действиях по обработке каждого изделия, обеспечивая массовое производство высоко кастомизированных продуктов, что и является одним из видений Индустрии 4.0. На сегодняшний момент рабочими группами, стандартизирующими эту концепцию, предусматривается использование стандарта RDF и подхода linked data, которые являются одними из основ графов знаний.
Итак, представим, что из множества исходных данных в определенной области мы построили полноценный граф знаний. Что же с ним делать и как графы знаний в принципе применяют?
Материалы прошедшей в мае 2019 года конференции в области графов знаний хорошо показывают, насколько широко такие графы применяются в индустрии.
- Прежде всего, крупнейшие банки (Goldman Sachs, Wells Fargo) используют графы знаний для анализа транзакций и поведения клиентов, а также для распознавания мошенничества и финансовых преступлений
- Консалтинговые компании составляют графы знаний из юридический документов (pwc, Capital One)
- Индустриальные компании создают графы для управления цепями поставок (eccenca)
- В сфере услуг и сервисов компании создают графы для поддержки клиентов (AirBnB) и анализа их взаимодействий, а также для создания интеллектуальных систем поддержки пользователей (чат-боты) (DiffBot)
- В области здравоохранения графы - прекрасная возможность представлять электронную карту пациента в машиночитаемом виде и связывать ее содержимое с существующими базами знаний (SnomedCT), публикациями (PubMed), системами поддержки в диагностике.
В целом, графы знаний получили широкое применение в бизнесе:
-
Они способствуют расчету комплексной бизнес-аналитики. Например, одна из самых дорогих частных компаний Palantir [12] использует динамические OWL онтологии и строит графы знаний для анализа контрагентов и цепочек поставок (так называемый corporate intelligence), поиска несоответствий в финансовых документах (financial compliance). Некоторые другие области включают здравоохранение, кибербезопасность, производство. Facebook поддерживает свой Social Graph [13] и использует его среди прочего для анализа связей между людьми и рекомендательными системами по рекламе.
-
Графы знаний упрощают интеграцию данных из разнородных источников, например, корпоративных информационных систем, представленных во множестве форматов в data warehouse или data lake. Такие решения как PoolParty Semantic Suite [14] от Semantic Web Company или Ultrawrap [15] от Capsenta создают и управляют корпоративными графами знаний, собираемыми из реляционных баз данных или слабоструктурированных источников.
-
Собственные графы знаний лежат в основе чат-ботов Amazon Alexa, Google Assistant, Apple Siri, которые могут ответить на самый широкий спектр вопросов от определения геолокации, например для поиска ближайших ресторанов или исторической справки о каком-либо местонахождении, до запросов о недвижимости и медицинских услугах.
Также создаются открытые графы знаний для множества предметных областей: медицина, лингвистика, технические и социальные науки. Такие графы аккумулируют знания не только в человекочитаемой форме как Wikipedia, но и в машиночитаемой, создавая базис для обучения машин решению интеллектуальных задач в этих областях. Так, например, портал Bio2RDF [16] является крупнейшим графом знаний медико-биологических наук. Граф объединяет 35 датасетов из 11 миллиардов триплетов, включая в том числе научные публикации из архива PubMed, который ведется с середины XX века, а также историю клинических испытаний лекарств, базы лекарственных средств, датасеты-описания белков, катализаторов, генов, их реакций, и многое-многое другое. Таким образом, в машиночитаемом виде, пригодном для обучения, представлена практически вся история достижения человечества в области наук о жизни.
Часть 3 - Научные проблемы
Наконец, помимо бизнес-задач графы знаний активно применяются в исследовании технологий обработки естественных языков и искусственного интеллекта в целом. А именно:
Распознавание именованных сущностей и извлечения отношений между ними (Named entity recognition и relation linking) на основе графов знаний, которые затем можно применить, например, в вопросно-ответных системах. Как определить, является ли слово в тексте именованной сущностью некоторого графа знаний?
Например, в вопросе “Обладателями каких наград являлись Юрий Гагарин и Сергей Королев?” при имеющемся графе Wikidata есть две сущности - имена собственные Юрий Гагарин и Сергей Королев, которые описаны в графе знаний, а также отношение “обладатель наград”, которое соответствует известному отношению award received (P166) в Wikidata. Определив верные сущности и отношения из вопроса, можно существенно увеличить точность работы таких вопросно-ответных систем и использовать эти наработки уже, например, в диалоговых системах.
Дополнение графов знаний и автоматический вывод новых фактов (knowledge graph completion, link prediction), которые позволяют решить задачу о том, как имея набор фактов в символьном (онтологическом) или векторном представлениях, вывести на их основе новые знания об описываемых сущностях. Соответственно, в онтологическом представлении чаще всего используются механизмы логического вывода, а в статистическом представлении — механизмы линейной алгебры, теории вероятностей и статистики.
Определение семантического сходства сущностей, которые в общем случае могут быть записаны синтаксически по-разному. Здесь стоит различать “степень близости”, то есть определяем ли мы близость априори разных сущностей в некотором контексте или пытаемся найти записанные по-разному дубликаты одной и той же сущности.
Например, Гете и Шиллер, разумеется, разные люди, но сходны в стиле своих писательских работ. С другой стороны, например, два лекарственных средства, выпускаемые под разными брендами, но имеющие одно и то же действующее вещество в основе. В онтологическом представлении графа знаний о лекарственных средствах сходство можно обнаружить, проследив, например, классовую иерархию или топологию подграфов, узлы которых могут ссылаться на одни и те же узлы большего графа. В векторном представлении графов может использоваться косинусный коэффициент сходства векторов. Найденное сходство, однако, может быть неинтерпретируемо, или иначе говоря, невозможно будет определить каким образом это значение сходства получено из-за высокой размерности векторного пространства.
Проверка корректности утверждений (fact-check) может применяться как для рассуждений об абстрактных вещах, например “Во всех ли университетах есть студенты”, так и для проверки высказываний из новостных заметок, которые часто страдают от фактологических ошибок или заведомо ложных утверждений.
Отраслевые конференции
Графы знаний активно обсуждаются как в академическом, так и бизнес-сообществах. К большим деловым форумам можно отнести
- Data.world
- Knowledge Graph Conference
На профильных научных конференциях графы знаний получают очень много внимания - анализ работ за прошедшие год-два позволит быстро вникнуть в курс дел.
- The Web Conf (WWW)
- International Semantic Web Conference (ISWC)
- Extended Semantic Web Conference (ESWC)
- Neural Information Processing Systems (NeurIPS)
- International Conference on Learning Representations (ICLR)
- AAAI Conference on Artificial Intelligence (AAAI)
- International Conference in Machine Learning (ICML)
- International Joint Conference on Artificial Intelligence (IJCAI)
- Annual Meeting of Association of Computer Linguistics (ACL / NAACL / AACL)
- Conference on Empirical Methods in NLP (EMNLP)
- Special Interest Group on Knowledge Discovery and Data Mining (SIGKDD)
- Special Interest Group on Management of Data (SIGMOD)
- International Conference on Very Large Databases (VLDB)
Часть 4. Hands-on demo
Рассмотрим как можно строить графы знаний при анализе текстов на естественном языке. Пусть на вход подается первый параграф статьи из Wikipedia, например, об Алане Тьюринге:
Alan Mathison Turing OBE FRS (23 June 1912 – 7 June 1954) was an English mathematician, computer scientist, logician, cryptanalyst, philosopher and theoretical biologist. Turing was highly influential in the development of theoretical computer science, providing a formalisation of the concepts of algorithm and computation with the Turing machine, which can be considered a model of a general-purpose computer. Turing is widely considered to be the father of theoretical computer science and artificial intelligence.
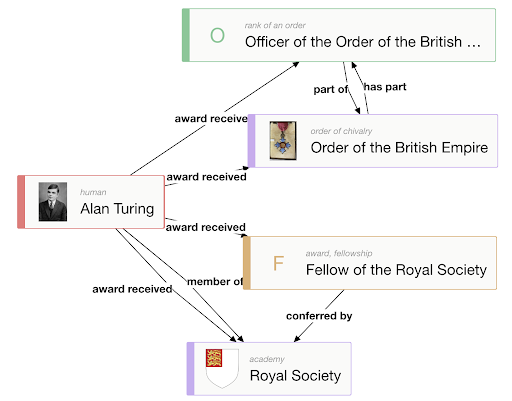
Наша задача здесь — выделить именованные сущности и связи между ними, объединив получившиеся факты в граф. Для этого мы используем платформу Metaphacts, подключенную к большому графу Wikidata. Прочитав текст, как правило, можно выделить несколько опорных точек, с которых можно начинать построение графа. Например, в случае Алана Тьюринга, OBE и FRS — аббревиатуры, свидетельствующие о наградах.
Им соответствует предикат award received, объекты которого можно поместить на граф.
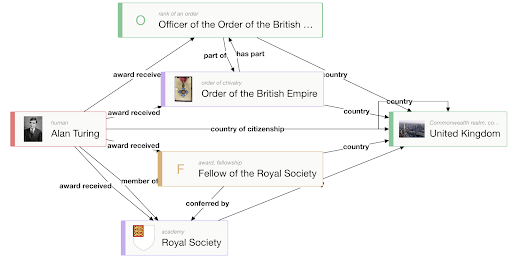
 Далее можно заметить, что в тексте говорится о гражданстве Тьюринга. Добавим предикат country of citizenship на граф. При этом, граф автоматически пополнится связями между наградами и страной (в случае наличия этих связей).
Далее можно заметить, что в тексте говорится о гражданстве Тьюринга. Добавим предикат country of citizenship на граф. При этом, граф автоматически пополнится связями между наградами и страной (в случае наличия этих связей).
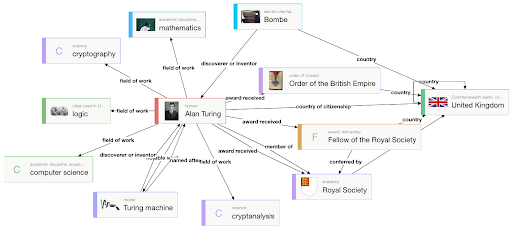
 Продолжая анализировать текст, найдем предикат field of work, который связан с математикой, логикой, криптографией и computer science. Значительные достижения можно обнаружить в предикатах notable work или discoverer/inventor, где мы найдем концепцию машины Тьюринга. Выбрав эти предикаты и объекты и расположив их на полотне, получим примерно следующий граф:
Продолжая анализировать текст, найдем предикат field of work, который связан с математикой, логикой, криптографией и computer science. Значительные достижения можно обнаружить в предикатах notable work или discoverer/inventor, где мы найдем концепцию машины Тьюринга. Выбрав эти предикаты и объекты и расположив их на полотне, получим примерно следующий граф:
Домашнее задание
С помощью Wikidata эндпойнта платформы Metaphacts исследуйте граф Викидаты: начните с вашего родного города и создайте граф диаметром не менее 5 (то есть от исходного города до самой удаленной сущности не менее пяти предикатов), используя не менее 20 сущностей и 5 разных типов предикатов.
Использованные материалы и ссылки:
[0] https://www.domo.com/assets/downloads/18_domo_data-never-sleeps-6+verticals.pdf
[1] https://wiki.dbpedia.org/
[2] https://en.wikipedia.org/wiki/Main_Page
[3] https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/
[4] https://wordnet.princeton.edu/
[5] http://rtw.ml.cmu.edu/rtw/
[NELL] http://ceur-ws.org/Vol-2317/article-02.pdf
[NELL 2] http://nell-ld.telecom-st-etienne.fr/
[6] https://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html
[7] https://www.wikidata.org/wiki/Wikidata:Main_Page
[8] https://lod-cloud.net/
[9] https://www.gartner.com/smarterwithgartner/5-trends-emerge-in-gartner-hype-cycle-for-emerging-technologies-2018/
[10] https://www.slideshare.net/AlanMorrison/collapsing-the-it-stack-clearing-a-path-for-ai-adoption
[11] https://www.gtai.de/GTAI/Navigation/EN/Invest/Industries/Industrie-4-0/Industrie-4-0/industrie-4-0-what-is-it.html
[12] https://www.palantir.com/
[13] https://developers.facebook.com/docs/graph-api/
[14] https://semantic-web.com/poolparty-semantic-suite/
[15] https://capsenta.com/
[16] http://bio2rdf.org/