Лекция 2
RDF, RDFS, OWL
| Материалы | Ссылка |
|---|---|
| Видео | YouTube |
| Слайды | |
| Конспект | здесь |
| Домашнее задание | link |
Видео
Графы и триплеты
Графы знаний характеризуются детальным описанием содержащихся в них сущностей и машинопонимаемыми логическими связями между ними. Существует два способа представления графов знаний. Первый способ, онтологическое представление, основан на формальной логике и семантике. Второй способ векторных представлений использует статистические механизмы для минимизации расстояний между близкими сущностями в многомерных пространствах. В этой и нескольких следующих лекциях мы сосредоточимся на онтологическом представлении.
Итак, термин ”граф знаний” дает некоторое представление о его конструкции и содержимом. Графовая модель позволяет моделировать физические и абстрактные сущности и связи между ними. Граф определяется классически как набор вершин и ребер \[ G = (V, E) | E \subseteq \mathbb{R}^{|V|\times|V|} \]
В графах знаний мы, однако, дополнительно отметим, что вершины и ребра могут иметь типы: \[\tau(v)=\gamma, v \in V, \tau(e)=\delta, e \in E \]. Следуя по цепочке концепций и связей можно исследовать близкие сущности и понятия, а также усиливать или уменьшать значимость конкретной связи между некоторыми сущностями или классами сущностей.
Термин “Классы сущностей”, в свою очередь, уже начинает намекать о содержимом графа, а именно знаниях. Как мы уже убедились в прошлой лекции, хранить знания в таблицах - несколько неестественный способ для человеческого мозга, который имеет сетевую природу, и здесь графы предлагают достойную альтернативу.
Для представления знаний в машиночитаемом виде используют формальные логики, а с понятием логики и знаний неразрывно связано и понятие семантики. С лингвистической трактовке семантика передает смысл символов некоторого формального или естественного языка. Здесь и далее мы будем иметь в виду формальную семантику, передающую смысл языков в математических терминах. Формальные логики предоставляют математический аппарат для представления смысла (интерпретации) языка.
Логик и семантик существует довольно много (пропозициональная логика, логика предикатов, модальная логика, логика первого порядка, и тд), и история их появления и развития достойна отдельной лекции. Рассматриваемые в курсе подходы основаны на логике первого порядка и дескрипционных логиках (как подмножество логики первого порядка) и теоретико-модельной семантике (семантике Тарского). Другими словами, они дают нам инструменты интерпретировать знания с ограничениями выразительности. Чем выразительнее логика, тем сложнее ее использовать для логического вывода.
Формальная логика и семантика для онтологического представления графов знаний опирается на такие стандарты консорциума WWW как RDF [0], RDFS [2] и OWL [1]. В совокупности они образуют стэк технологий и стандартов, называемый Semantic Web Layer Cake:
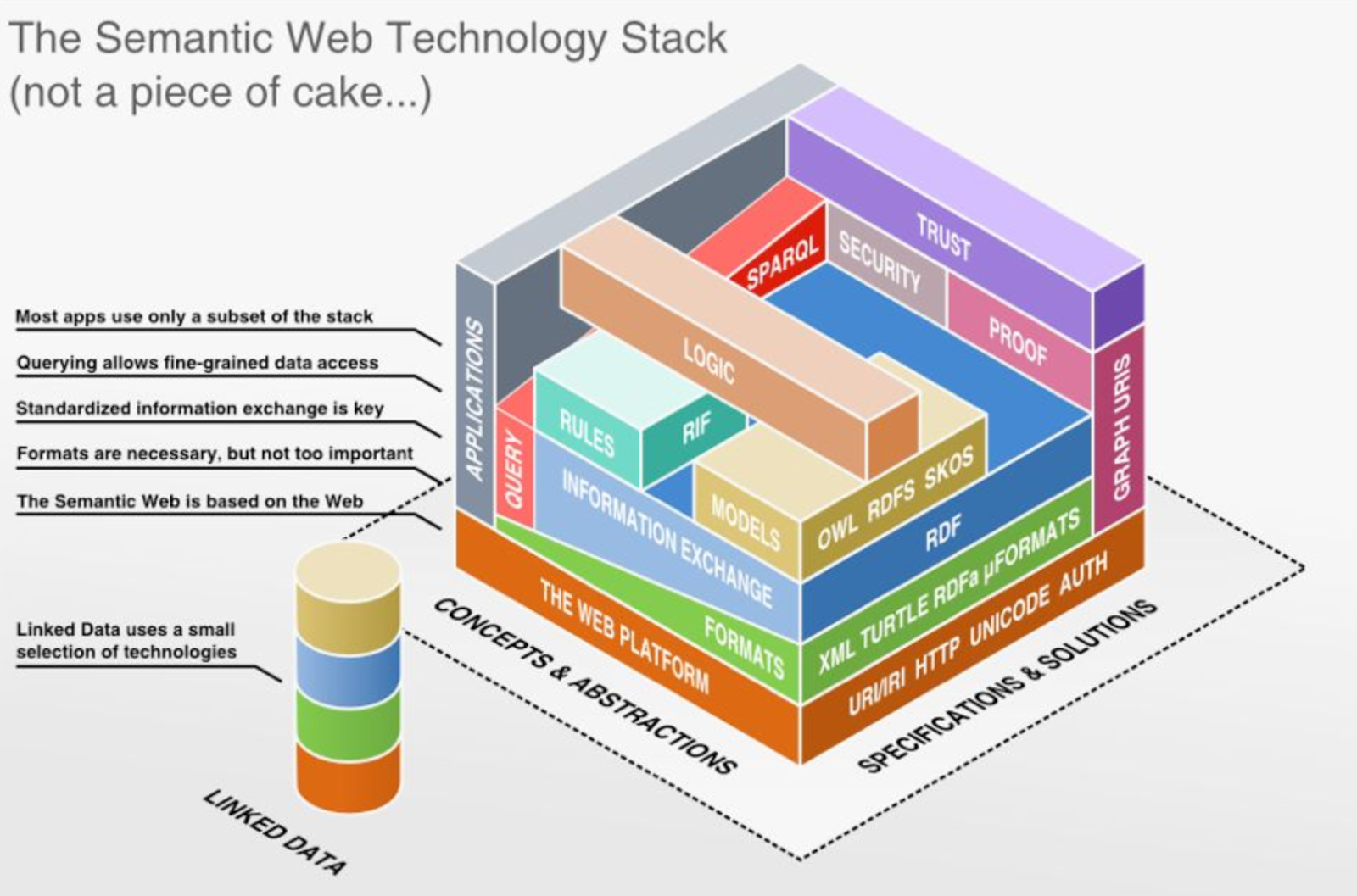
На нижнем уровне, обозначающем базовые средства передачи информации в сети, находятся уникальные идентификаторы ресурсов (URI), передающиеся по протоколу HTTP символами Юникода с возможностью аутентификации и авторизации. На уровне выше находятся форматы - синтаксис представления данных. Среди них XML, Turtle, RDFa, JSON-LD и другие. Мы рассмотрим самые популярные и используемые дальше в этой лекции.
На следующем уровне представлен собственно метод представления данных - модель RDF, которая вводит начальную семантику описываемых ресурсов.
Поднимаясь уровнем абстракции выше, мы приходим к расширение логической модели и выразительности RDF с помощью стандартов RDFS, OWL, SKOS, также вводом формата описаний логических правил “если-то”. Правила могут описываться, например, с помощью стандарта RIF, SWRL или SPIN. Все логические расширения RDF так или иначе ведут к формальной логике, а именно дескрипционным логикам и логике первого порядка.
Для запросов к знаниям, представленным в RDF, используется язык запросов SPARQL, который связывает графы знаний с приложениями, опирающимися на графы знаний. У SPARQL может вводить и поддерживать собственные логические механизмы, а также служит для управления доступом к знаниям в зависимости от параметров пользователя, отправляющего запрос.
Стэк также предусматривает средства обеспечения достоверности и корректности представляемых знаний посредством указания и сохранения источников знаний - как на уровне отдельного утверждения, так и на уровне коллекции фактов (VoID, SHACL, ShEx). Рассмотрим некоторые ключевые технологии подробнее.
RDF
Стандарт RDF (Resource Description Framework) определяет модель триплета “субъект - предикат - субъект” или “субъект - предикат - объект” . То есть сущность — “субъект” может быть связана с другой сущностью или простым значением — объектом — через некоторое свойство — предикат. Компоненты триплета, т.е. что можно в нем использовать:
-
URI (Uniform Resource Identifier) - универсальный и уникальный идентификатор ресурса. Как правило, выражен в юникоде. Концепция семантического веба (Semantic Web) и связанных данных (Linked Data) способствует принятию URL-подобных идентификаторов, чтобы они могли ссылаться на описываемые в Сети сущности. Например, идентификатор Университета ИТМО может содержать http://en.ifmo.ru/ITMO_University, где префикс http://en.ifmo.ru/ - адрес в Интернете, разрешающийся в веб-ресурс. Для удобства полные URI можно сокращать в префиксы и использовать запись
prefixName:Entity. Например, термины RDF имеют стандартный префиксrdf:, что заменяет http://www.w3.org/1999/02/22-rdf-syntax-ns#. -
Литералы - простые значения - строки или числа. В расширениях RDFS определены существующие в XML числовые, строковые и логические типы данных, например целое число, дата, строка, истина/ложь. Более мощные выразительные стандарты (OWL) позволяют создавать собственные типы данных, например, “все простые числа” или “числа, делящиеся на два”. Строковым значениям, как правило, назначается идентификатор использованного языка. Это считается хорошим тоном и способствует более аккуратным ответам на запросы. Так,
“Университет ИТМО”@ruобозначает строку на русском языке, а“ITMO University”@en- строку на английском. -
Неименованные вершины (blank nodes) - анонимно заданные сущности без идентификатора или литерала, могут содержать другие отношения и значения. Используется в том числе для описания сложных предикатов и реификации, о которых поговорим позднее.
Модель RDF определяет, как знания о сущности представлять в виде триплетов, образующих ориентированный граф. Как правило, семантика и выразительность стандарта или модели зависит от набора ключевых слов (vocabulary), для которых эта семантика определена в стандарте. Семантика RDF довольно проста и ограничена набором специальных предикатов (в т.ч. rdf:type, rdf:Property, rdf:subject, rdf:predicate, rdf:object, rdf:first, rdf:rest, rdf:value, rdf:nil, rdf:List). В общем случае можно сказать, что RDF позволяет делать и выводить утверждения о принадлежности ресурса к некоторому множеству с помощью атрибута rdf:type и назначать ресурсам атрибуты-литералы.
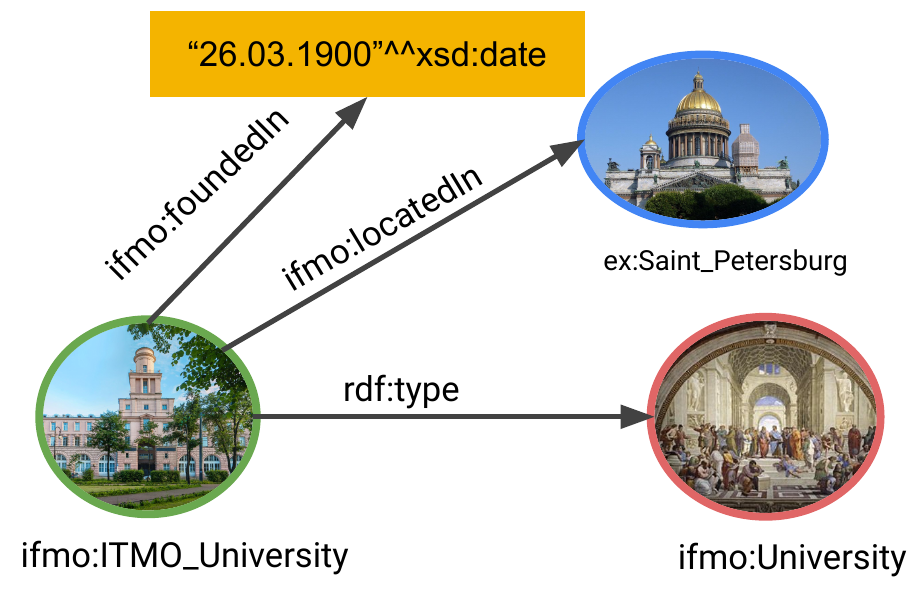
Например, триплет “Университет ИТМО - находится в - Санкт-Петербург” связывает именованные сущности Университет ИТМО и Санкт-Петербург посредством предиката “находится в”. А триплет “Университет ИТМО - основан - 26.03.1900” связывает атрибут “основан” сущности Университет ИТМО со значением даты 26 марта 1900 года. Триплет “Университет ИТМО - rdf:type - Университет” говорит о принадлежности сущности “Университет ИТМО” к множеству университетов.
Сериализации: Turtle, JSON-LD
Рассмотрим формат записи RDF-данных. RDF, по сути, является логической моделью, не зависящей от конкретного синтаксиса. В стандарте, однако, для наглядности примеров используются XML/RDF и Turle. Один из самых простых и понятных для работы форматов - Turtle (ttl). Преамбула содержит используемые префиксы, а далее триплеты записываются в текстовом формате. Для улучшения читаемости пары предикат-значение можно группировать по принадлежности в одному субъекту, несколько значений группировать к одному предикату, создавать неименованные вершины, а также создавать логические аксиомы RDFS и OWL. Пример графа выше, выраженный в Turtle, будет выглядеть следующим образом:
@prefix ifmo: <http://en.ifmo.ru/> .
@prefix ex: <http://example.org/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
ifmo:ITMO_University rdf:type ifmo:University ;
ifmo:locatedIn ex:Saint_Petersburg ;
ifmo:foundedIn “26.03.1900”^^xsd:date .
JSON-LD - подвид JSON, использующий разметку в стиле JSON для аннотации ресурсов, в тч веб-ресурсов. Граф в JSON-LD может выглядеть:
{
"@graph" : [ {
"@id" : "ifmo:ITMO_University",
"@type" : "ifmo:University",
"foundedIn" : "26.03.1900",
"locatedIn" : "ex:Saint_Petersburg"
} ],
"@id" : "urn:x-arq:DefaultGraphNode",
"@context" : {
"foundedIn" : {
"@id" : "http://en.ifmo.ru/foundedIn",
"@type" : "http://www.w3.org/2001/XMLSchema#date"
},
"locatedIn" : {
"@id" : "http://en.ifmo.ru/locatedIn",
"@type" : "@id"
},
"ex" : "http://example.org/",
"rdf" : "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"xsd" : "http://www.w3.org/2001/XMLSchema#",
"ifmo" : "http://en.ifmo.ru/”
}
}
Стоит заметить, что в большинстве случаев графы не создаются вручную набором текста, а генерируются автоматически из более визуальных средств моделирования или других источников данных. На Turtle основан язык запросов SPARQL и множество связанных нотаций и инструментов, например, RML - стандарт отображения XML/CSV/JSON/реляционных БД в RDF.
RDFS
Логический базис RDF расширяется родственными стандартами RDFS (RDF Schema) [2] и OWL (Web Ontology Language)[1], которые вводят базовые аксиомы формальной логики, в том числе дескрипционной логики, что позволяет осуществлять логический вывод на основе триплетов. RDFS (RDF Schema) - расширение модели RDF, вводящее больше выразительных элементов (vocabulary), имеющих определенную в стандарте формальную семантику:
- Понятие класса - через
rdfs:Classex:University rdf:type rdfs:Class - Иерархию классов - через
rdfs:subClassOfex:University rdfs:subClassOf ex:EducationalInstitution - Иерархию предикатов - через
rdfs:subPropertyOfex:locatedInCity rdfs:subPropertyOf ex:locatedIn - Области определения и значений предиката - через
rdfs:range,rdfs:domainex:locatedInCity rdfs:range ex:City (ex:City - класс) ex:locatedInCity rdfs:domain ex:PhysicalObject -
Типы данных из XML:
xsd:date,xsd:string,xsd:int,xsd:boolean, и т.д. -
Предикаты для аннотаций и текстовых значений. Например, значением rdfs:label всегда должна быть строка (желательно с тэгом языка):
ex:ITMO_University rdfs:label “Университет ИТМО”@ruЗначения таких предикатов не участвуют в логическом выводе новых фактов. - Базовый аппарат для реификации - утверждений об утверждениях - что рассмотрим в следующей лекции.
RDFS вводит 13 базовых правил [3] логического вывода на графе, использующем RDFS vocabulary. Например на основе области значений предиката расположения в городе ex:locatedInCity - ex:City (город) можно вывести класс конкретного ресурса в позиции объекта триплета и получить, что Санкт-Петербург относится к классу городов:
ex:locatedInCity rdfs:range ex:City .
ex:ITMO_University ex:locatedInCity ex:Saint_Petersburg .
-------
ex:Saint_Petersburg rdf:type ex:City .
Заметим, однако, что RDFS по-прежнему не позволяет выражать отрицание. Отрицание и более выразительные логические конструкции поддерживаются в стандарте OWL (текущая версия OWL 2).
OWL
Наиболее выразительный на настоящее время стандарт представления знаний - OWL - Web Ontology Language - язык описаний онтологий. Первая версия стандарта была принята в 2004 году, более новая датирована 2009 годом. Основное отличие OWL от других формализмов в том, что OWL основан на подмножестве логики первого порядка - дескрипционной логике. В общем случае дескрипционных логик может быть много, так как они образуются логическими компонентами, которые обозначаются собственной буквой. OWL 1 2004 года основан на логике SHOIN(D), тогда как OWL 2 2009 года на SROIQ(D), чьи отличия мы рассмотрим немного позднее.
На чем основан OWL?
Классы, предикаты и экземпляры классов как основные способы описания ресурсов.
Гипотеза об открытом мире - другими словами, отсутствие информации не говорит об истинности или ложности информации. Например, утверждение knows(Alice, Bob) в замкнутом мире обозначало бы истинность только того, что Алиса знакома с Бобом, и в процессе логического вывода только на этот предикат алгоритм давал бы положительный ответ, а на подобные, но содержащие вместо Bob другие литералы ответ был бы отрицательным. В открытом мире, таких предположений алгоритмом вывода не делается, а учитывается лишь то, что явно определено в базе знаний. Другими словами, утверждение выше не говорит, что Алиса знает только Боба, напротив, делается предположение, что Алиса может знать и других людей.
Гипотеза об уникальности сущностей не выполняется, т.е. нужно указывать отдельно и специально, что две сущности различаются.
Выразительность OWL
Почему мы не можем сразу использовать логику первого порядка для представления знаний? Из математической логики известно, что логика первого порядка алгоритмически полуразрешима, то есть существует алгоритм, который за конечное время может подтвердить если некоторое предложение в данной теории в действительности верно, иначе может работать бесконечно долго. Как правило, чем более экспрессивна логика, тем хуже ее алгоритмическая разрешимость. Чтобы получить разрешимые логики (хотя бы в экспоненциальной сложности) экспрессивность нужно уменьшать. Дескрипционные логики позволяют получить довольно экспрессивные, но алгоритмически разрешимые теории. Так, OWL 1 основан на логике SHOIN(D), что означает:
- S - логика ALC с транзитивными предикатами (если
knows- транзитивный предикат иknows(Alice, Bob),knows(Bob, Eve), то следует, чтоknows(Alice, Eve) - H - иерархия классов и предикатов, то есть один предикат может быть более обобщенной версией второго, один класс может быть подклассом второго
- О - классы сущностей, составленные из прямого перечисления экземпляров
- I - инверсные предикаты, например
hasFather(A, B),hasChild(B, A):hasFatherиhasChild- инверсные предикаты - N - ограничения на кратность использования предиката по отношению к какой-либо сущности, например у экземпляра класса Parent должен быть есть хотя бы один предикат hasChild
- (D) - типы данных и возможность создания собственных типов Кванторы общности и существования, а также конъюнкция, дизъюнкция и отрицание классов.
В дальнейшем, стандарт получил поддержку нескольких более экспрессивных конструкций SROIQ(D), где новые буквы обозначают:
- R - рефлексивность и иррефлексивность предикатов (например, если
knows- рефлексивный предикат, то субъект и объект триплета могут быть одинаковыми - то естьknows(A, A)- A знает сам себя); несовместность предикатов; цепи предикатов (например,hasMother o hasHusband -> hasFather) - Q - квалифицированные (то есть с указанием класса значения) ограничения на кратность использования предикатов (например, пицца должна иметь минимум 2 предиката
hasTopping, чьи значения должны принадлежать классуTopping).
У OWL и OWL 2 существуют еще более ограниченные профили меньшей выразительности, но имеющие лучшие свойства алгоритмической разрешимости.
OWL аксиомы
Как влияют логические конструкции на структуру графа? Вывод фактов часто ведет к появлению неявно заданных предикатов между узлами, что мы будем рассматривать в задаче предсказания связей в графе. Логический вывод также может привести к изменению класса узла, что мы будем рассматривать в задаче классификации узлов и целых графов.
Формат OWL как и RDF может быть сериализован в несколько синтаксисов. Одни из самых популярных и легких для чтения человеком сериализаций - OWL Manchester Syntax и Turtle. Попробуем представить следующее высказывание (“Музыкант пишет песни и если пишет, то только песни”):
Musician ≣ ∀writes.Song ⨅ ∃writes.Song
В OWL Manchester Syntax высказывание можно записать в таком виде:
Class: Musician
EquivalentTo:
(writes some Song)
and (writes only Song)
В Turtle оно же будет выглядеть так:
:Musician rdf:type owl:Class ;
owl:equivalentClass [ owl:intersectionOf (
[ rdf:type owl:Restriction ;
owl:onProperty :writesSongs ;
owl:someValuesFrom :Song ]
[ rdf:type owl:Restriction ;
owl:onProperty :writesSongs ;
owl:allValuesFrom :Song] ) ;
rdf:type owl:Class ] .
Как мы уже знаем, в OWL существуют классы, предикаты и экземпляры классов (инстансы). Все они могут объявляться как простым триплетом, так и более сложным высказыванием - OWL аксиомой. Стандарт предусматривает два уже определенных класса:
owl:Thingкак класс, содержащих все инстансы С ⨆ Сowl:Nothingкак класс - пустое множество С ⨅ С
Классы объявляются с помощью предиката owl:Class:
:University rdf:type owl:Class .
С помощью аксиом можно создавать сложные классы, заданные пересечением, объединением или дополнением других классов или ограничений на предикаты.
Экземпляры классов могут задаваться или принадлежностью к классу, или как NamedIndividual:
:ITMO_University rdf:type :University .
:ITMO_University rdf:type owl:NamedIndividual .
Предикаты в OWL подразделяются на объектные и литеральные.
Объектные предикаты (Object property) имеют в области значений экземпляры классов, а литеральные (Data property) - XML типы данных (строки, числа, истина/ложь, даты, и тд)
:hasStudent rdf:type owl:ObjectProperty ;
rdfs:range :Student ;
rdfs:domain :University .
Предикат hasStudent определен для класса университетов и имеет своим значением инстанс класса студентов.
:foundedIn rdf:type owl:DatatypeProperty ;
rdfs:range xsd:NonNegativeInteger ;
rdfs:domain :University
Предикат foundedIn определен для класса университетов, но имеет своим значением положительное целое число как тип, определенный в стандарте XML.
Объектные предикаты в OWL могут иметь дополнительные свойства:
- Транзитивность -
owl:TransitivePropertyTransitiveProperty(locatedIn) locatedIn(ITMO, Saint Petersburg) locatedIn(Saint Petersburg, Russia) -> locatedIn(ITMO, Russia) - Симметричность -
owl:SymmetricPropertycompetitor(ITMO, SPbSU) -> competitor(SPbSU, ITMO) - Асимметричность -
owl:AsymmetricPropertypartOf(part, whole) -> предикат partOf(whole, part) использовать нельзя - Рефлексивность -
owl:ReflexivePropertyadvertises(ITMO, ITMO) - Иррефлексивность -
owl:IrreflexivePropertyisParentOf(x, y) -> x и y - разные инстансы - Функциональность -
owl:FunctionalPropertyhasRector(ITMO, PersonA) hasRector(ITMO, PersonB) -> PersonAPersonB - Обратная функциональность -
owl:InverseFunctionalPropertyhasRector(UniA, PersonA) hasRector(UniB, PersonA) -> UniA = UniB - Несовместность предикатов -
owl:propertyDisjointWith- два инстанса не могут быть связаны несовместными предикатамиhasParent owl:propertyDisjointWith hasChild hasParent(x,y) -> предикат hasChild(x,y) использовать нельзя
Один из мощных механизмов OWL - квалифицированные ограничения (qualified restrictions) на предикаты, например, с их помощью можно составить утверждение “Успешный автор имеет как минимум один бестселлер”, что на логике первого порядка:
SuccessfulAuthor ⊑ 1 notableWork.Bestseller
В Turtle аксиома может быть выражена следующим образом:
:SuccessfulAuthor a owl:Class ;
rdfs:subClassOf [
a owl:Restriction;
owl:onProperty :notableWork;
owl:minQualifiedCardinality 1;
owl:onClass :Bestseller ] .
В OWL можно строить и более продвинутые конструкции, включая, например, отношения над предикатами (hasMother(x, y) , husbandOf(z, y) -> hasFather(x, z)) и строить логические правила “если - то”, постулирующиеся другими стандартами (SWRL, SPIN). В совокупности OWL представляет собой выразительный и алгоритмически разрешимый стандарт представления знаний, опирающийся на графовую модель.
Ризонеры
Как заставить логические правила работать и выводить новые факты из уже имеющихся на основе RDFS или OWL аксиом? Для этого предназначены машины логического вывода (ризонеры, reasoners), которые на входе получают RDF граф с логическими аксиомами и выводят новые триплеты. Основные задачи, решаемые ризонером - классификация сущностей и создание новых связей между сущностями. Другими словами на языке графов, ризонеры выводят новые атрибуты вершин или создают новые ребра между вершинами.
Одна из отличительных особенностей ризонеров в том, что они приводят логическое обоснование каждому выведенному факту, чего не могут достичь системы машинного обучения на статистических механизмах. Однако, недостаток ризонеров в быстро растущем времени работы в зависимости от сложности логических конструкций и размера графа. OWL определяет несколько облегченных профилей, где можно использовать только строго заданный набор логических конструкций для ускорения работы ризонеров. Несмотря на это, масштабируемость ризонеров и механизмов символьных вычислений в целом сильно отстает от масштабируемости механизмов статистических вычислений, и это одно из важных направлений в исследованиях - как совместить лучшее из двух миров: скорость и масштабируемость систем машинного обучения на статистике и логическая строгость и обоснованность символьных систем.
Онтологии
Итак, граф знаний концептуально состоит из двух частей: схема данных графа и собственно его наполнение. Схему данных часто называют TBox (Terminology Box), или онтологией, а наполнение ABox (Assertion Box), или фактами.
Часть графа знаний, описывающая абстрактные концепции и связи между ними на высоком уровне, иначе еще называется онтологией. Существует множество определений понятия “онтология”, но все они сходны в том, что онтология — формализованная модель некоторой области знаний, согласованная с экспертами этой области. В процессе наполнения такой модели экземплярами реальных данных и получается граф знаний.
Онтологии могут быть разной степени выразительности как мы видим из RDFS и OWL. Создание онтологий (и графов знаний в целом) — тема отдельной лекции. Здесь же мы скажем, что это чаще всего итеративный процесс, включающий в себя взаимодействие с экспертами определенной области знаний и инженерами по знаниям, которые способны эти знания записать на формальном языке онтологий (например, OWL). Активно развивающаяся область исследований — автоматическое создание онтологий без участия человека из слабоструктурированных данных (например, текста или таблиц).
Если стандартов создания онтологий относительно немного, то онтологий как схем графов знаний, созданных на основе этих стандартов, уже очень много. Одна из крупнейших онтологий SNOMED-CT содержит сотни тысяч аксиом в области медицины и входит в программу подготовки медицинских специалистов в США. Соответственно, медицинские графы знаний стараются использовать эту стандартную терминологию. Для создания тезаурусов и иерархий используется онтология SKOS.
А для описания общих знаний, использующихся в Wikipedia, существуют онтологии из DBpedia, Wikidata и YAGO. Графы знаний, использующие одну или похожие онтологии, легче связывать между собой и обогащать данными релевантных графов. На этой идее основана концепция Linked Open Data (LOD). Ресурс Linked Open Vocabularies (LOV) содержит описания и ссылки на почти все известные онтологии в самых разных доменах - от финансов до производства.
RDF vs RDB
Как же граф знаний в целом отличается от реляционных баз данных?
Во-первых, семантическая модель RDF по своей природе полуструктурированная, то есть, если в схеме данных существует триплет “количество учащихся - область определения - Учебное заведение”, то это НЕ значит, что каждый экземпляр “Учебного заведения” ОБЯЗАН иметь значение свойства “количество учащихся”. Граф корректен и без такого предиката, тогда как в реляционных базах данных если введено такое отношение, то ему обязательно должно быть присвоено некоторое значение, пускай даже N/A, если точное число неизвестно.
Из этого вытекает вторая отличительная особенность графов знаний RDF: они используют модель открытого мира вместо модели закрытого мира, присущей классическим базам данных. Другими словами, если некоторый факт явно не присутствует в графе, то на соответствующий вопрос о существовании данного факта можно ответить “мы не знаем”, тогда как в реляционных моделях ответ всегда будет “нет”.
Демо: создание графов в WebVOWL Editor
Видео с 48:40.
Ресурс: WebVOWL Editor
Домашнее задание
С помощью WebVOWL Editor попробуйте концептуализировать область вашей работы в небольшую онтологию из не менее 10 классов и 5 объектных и литеральных предикатов.
Использованные материалы и ссылки:
[0] https://www.w3.org/TR/rdf11-concepts/
[1] https://www.w3.org/TR/owl2-overview/
[2] https://www.w3.org/TR/rdf-schema/
[3] https://www.w3.org/TR/rdf-mt/#RDFSRules