Лекция 5
Интеграция данных в графы
| Материалы | Ссылка |
|---|---|
| Видео | YouTube |
| Слайды | |
| Конспект | здесь |
| Домашнее задание | link |
Видео
Зачем интегрировать?
Составление графов знаний - отдельная задача, стоящая на стыке семантических технологий, баз данных и извлечения данных. Как правило, исходные данные не организованы как граф, потому процесс интеграции данных в графы знаний зависит от набора и форматов исходных данных. Различают два подхода к построению графов знаний: семантическая интеграция данных из гетерогенных полу- и структурированных источников (например, когда речь идет о реляционных базах данных) и извлечение знаний из неструктурированных источников (например, текстовые документы без разметки). В этой лекции мы сосредоточимся на составлении графов из полу- и структурированных источников.
Semantic Data Integration
При наличии разнообразных источников данных их интеграция в граф вызывает несколько важных проблем:
- Неоднородность форматов (например, JSON, CSV, и XML) - когда данные представлены разным синтаксисом и разными моделями
- Семантическая неоднородность - когда источники оперируют разными уровнями абстракции (например, люди - артисты, животные - кошки)
- Распределенность данных - источники могут быть разными базами данных и ресурсами, находящимися физически в разных локациях, где постоянный доступ не гарантируется или осуществляется с задержкой
- Неоднородность именования - источники могут описывать одну и ту же физическую сущность под разными именами (например, “Кронверкский проспект, дом 49” и “Кронверский пр-т, д. 49”
- Неоднозначность и эволюция данных - источники могут со временем содержать разную информацию, и тогда нужно учитывать актуальность данных на текущий момент времени
Для интеграции полу- и структурированных источников в граф знаний используют подход с использованием семантических технологий (semantic data integration). Система интеграции данных (integration system, IS) определяется [0] как:
IS = <O, S, M>
Где O - множество концептов в некоторой общей схеме данных (например, онтология), \[ S={S_1, …, S_n} \] - множество источников данных с собственными схемами, M - множество отображений (маппингов, mappings) между источниками S и глобальной схемой О.
Для иллюстрации понятий системы интеграции данных зададим глобальную онтологию:
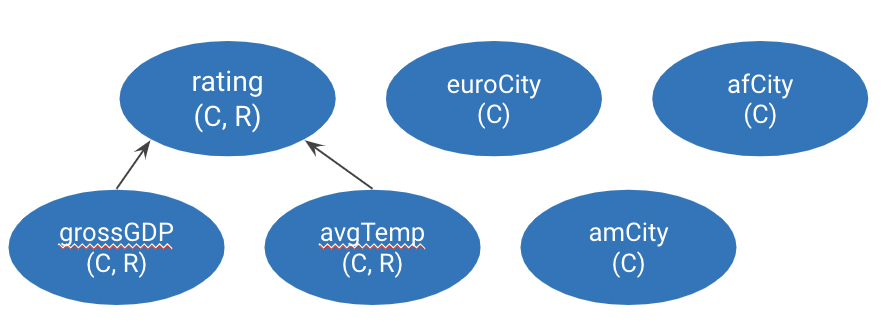
grossGDP rdf:type rdf:Property . # grossGDP(C, R)
avgTemp rdf:type rdf:Property . # avgTemp(C, R)
rating rdf:type rdf:Property . # rating(C, R)
grossGDP rdfs:subPropertyOf rating .
avgTemp rdfs:subPropertyOf rating .
euroCity rdf:type rdfs:Class . # euroCity(C)
amCity rdf:type rdfs:Class . # amCity(C)
afCity rdf:type rdfs:Class . # afCity(C)
Пусть источники имеют схему, определяющую следующие предикаты:
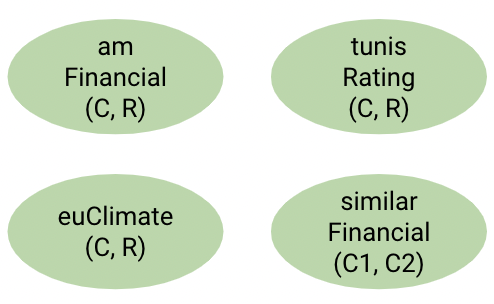
amFinancial rdf:type rdf:Property . # amFinancial(C, R) where C - some american city, R - financial rating
euClimate rdf:type rdf:Property . # euClimate(C, R) where C - some eu city, R is a climate rating
tunisRating rdf:type rdf:Property . # tunisRating(T, R) where T - Tunis, R - financial and climate ratings
similarFinancial rdf:type rdf:Property . # similarFinancial(C1, C2) - relates two american cities C1 and C2
Как правило, в системе интеграции данных запросы поступают к глобальной схеме. Маппинги составляются для переписывания запросов к локальным источникам в их поддерживающейся схеме данных. Составление маппингов чаще всего происходит вручную, но начинают появляться механизмы автоматического создания простых маппингов. Существует три механизма составления маппингов между глобальной онтологией и источниками: Global-as-View (GAV), Local-as-View (LAV), Global-&-Local-as-View (GLAV).
Global-as-View
Механизм Global-as-View (GAV) предусматривает определение сущностей глобальной онтологии O в терминах локальных источников S. Под определением понимается конъюнкция известных предикатов (конъюнктивное правило, conjunctive rule). Для примера выше GAV маппинги могут выглядеть следующим образом:
amCity(C) :- amFinancial(C,R)
grossGDP(C,R) :- amFinancial(C,R)
euroCity(C) :- euClimate(C,R)
avgTemp(C,R) :- euClimate(C,R)
grossGDP(“Tunis”,R) :- tunisRating(“financial”, R)
avgTemp(“Tunis”, R) :- tunisRating(“climate”, R)
afCity(“Tunis”)
amCity(C1) :- similarFinancial(C1,C2)
amCity(C2) :- similarFinancial(C1,C2)
grossGDP(C1,R) :- similarFinancial(C1,C2), amFinancial(C2, R)
Все шесть сущностей глобальной схемы определены через термины источников S. Разумеется, может существовать несколько вариантов отображений, что, в свою очередь, увеличивает сложность процесса переписывания запросов. Например, следующий запрос можно переписать по-разному:
query(C) :- grossGDP(C,R), amCity(C)
query_1(C) :- amFinancial(C,R), amFinancial(C,C2)
query_2(C) :- similarFinancial(C,C2), amFinancial(C2,R),similarFinancial(C1,C2)
В исследованиях было доказано [1], что нижняя граница сложности переписывания запросов - экспоненциальная и суперполиномиальная в случае прямого переписывания без ограничений в зависимости от количества возможных маппингов. Ввод ограничений на процесс переписывания снижает сложность до полиномиальной.
Подход GAV применяют, когда глобальная схема может часто меняться, тогда как схема локальных источников всегда стабильна. К преимуществам GAV относят и полиномиальную сложность переписывания запросов по сравнению с другими подходами.
Local-as-View
Механизм Local-as-View (LAV) предусматривает определение сущностей источников S через термины глобальной онтологии O. В нашем примере LAV-маппинги могут выглядеть следующим образом:
amFinancial(C,R) :- amCity(C),grossGDP(C,R)
euClimate(C,R) :- euCity(C),avgTemp(C,R)
tunisRating(“financial”,R) :- afCity(“Tunis”), grossGDP(“Tunis”, R)
tunisRating(“climate”,R) :- afCity(“Tunis”), avgTemp(“Tunis”,R)
similarFinancial(C1,C2) :- amCity(C1),amCity(C2),grossGDP(C1,R),grossGDP(C2,R)
Тогда переписывание такого же запроса к глобальной схеме:
query(C) :- grossGDP(C,R),amCity(C)
query_1(C) :- amFinancial(C,R)
query_2(C) :- similarFinancial(C,C2)
При анализе подхода LAV стоит учитывать проблему вложенности запросов (query containment), т.е. может ли переписанный запрос вернуть то же самое количество результатов, что и исходный. В настоящее время это NP-полная задача.
LAV эффективен, когда глобальная схема остается постоянной, а схемы источников могут меняться. LAV маппинги в этом случае могут эффективно адаптироваться к новым источникам, тогда как GAV каталог придется переписывать полностью.
Global-And-Local-as-View
Механизм Global-And-Local-as-View (GLAV) предусматривает определение комбинации терминов глобальной онтологии О через комбинацию терминов источников S.
amCity(C1),amCity(C2),grossGDP(C1,R),grossGDP(C2,R) :-
amFinancial(C1,R), similarFinancial(C1,C2)
Проблема определения вложенности запроса в GLAV тоже актуальна, однако, GLAV используют, когда источники S могут быть относительно просто описаны. Но если схема источников меняется часто, то поддержка GLAV маппингов может быть затруднительна.
Материализация vs Федерализация
Создав отображения источников на глобальную схему, существует два пути их применения и организации интеграции: материализация источников, когда гетерогенные данные консолидируются в одном месте в одном формате, а маппинги служат для преобразования исходных форматов в целевой; и федерализация источников, когда источники остаются в исходных форматах, но маппинги используются для переписывания запросов с языка глобальной схемы на языки локальных источников.
Материализация данных (консолидация, materialization) эффективна, когда данные статичны и часто не изменяются, тогда преимуществом будет локальный доступ ко всем преобразованным данным.
Федерализация данных (virtualization) эффективна в случае большого количества изменяющихся источников, или когда прямая материализация невозможна. Преимуществом будет сохранение данных в оригинальных форматах, что, однако, требует надежного соединения с удаленными источниками для доступа “на лету” во время обработки запроса.
Материализация данных (Physical Integration)
В сценарии интеграции данных через материализацию предполагается преобразование разнородных форматов источников данных к одному. В случае графов знаний подразумевается трансформация данных в RDF-граф с помощью механизмов Extract - Transform - Load (ETL).
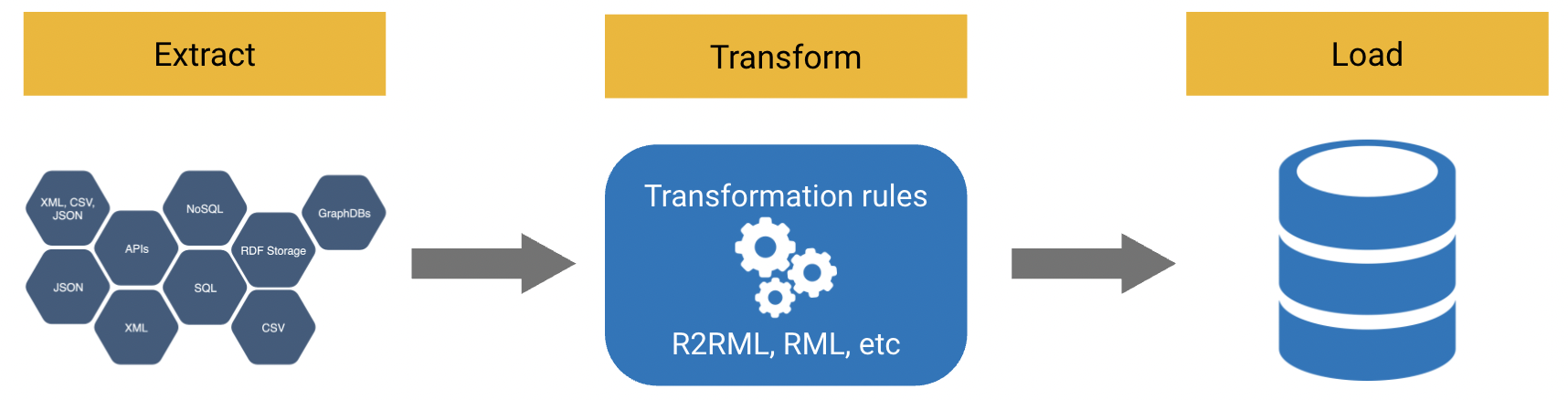
ETL состоит из трех шагов. Extract предполагает выделение данных, подлежащих конвертации, из общего объема. Transform выполняет процесс физического преобразования форматов данных с помощью разработанных отображений (маппингов). Наконец, на шаге Load преобразованные данные загружаются в единое хранилище, называемое Data Warehouse. Уже на базе Data Warehouse строятся системы аналитики и отчетности.
Преобразование содержимого реляционных баз данных в RDF - предмет рекомендаций консорциума W3C RDB2RDF (Relational Databases to RDF). Рекомендации описывают языки создания отображений с реляционных схем на графы - Direct Mapping и R2RML (RDB 2 RDF Mapping Language). Программы преобразования, поддерживающие эти языки, обрабатывают реляционные БД с помощью маппингов в целевой RDF граф. Ниже мы рассмотрим R2RML как более гибкий инструмент создания целевых графов.
R2RML
R2RML был принят в 2012 году как рекомендация W3C [2] для задач преобразования реляционных БД в RDF. R2RML использует синтаксис Turtle и вводит префикс rr:
rr: http://www.w3.org/ns/r2rml#
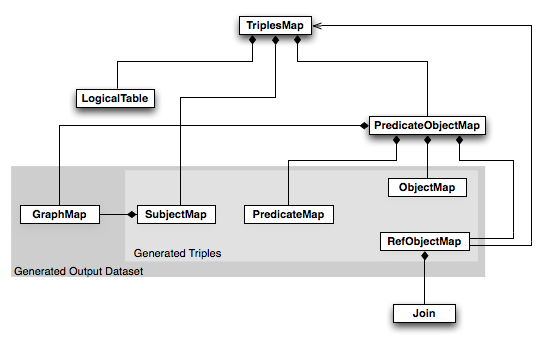 Логическая структура R2RML
Логическая структура R2RML
На логическом уровне R2RML оперирует следующими понятиями:
- Логическая таблица (logical table), обозначающая реляционную таблицу в исходной БД, или представление (view) БД как результат некоторого запроса, или SQL запрос
- Отображение триплетов (triples map), с помощью которых строки таблицы отображаются в RDF триплеты. Отображение - набор правил, создающих граф:
- Отображение субъекта (subject map) - способ задания URI генерируемой сущности. URI часто генерируется из первичного ключа таблицы
- Отображение пары предикат-объект (predicate-object map), задающих способ генерации предиката и соответствующего объекта (сущности или литерала)
Рассмотрим для примера создание правил преобразования в RDF двух таблиц EMP (Employee) и DEPT (Department):
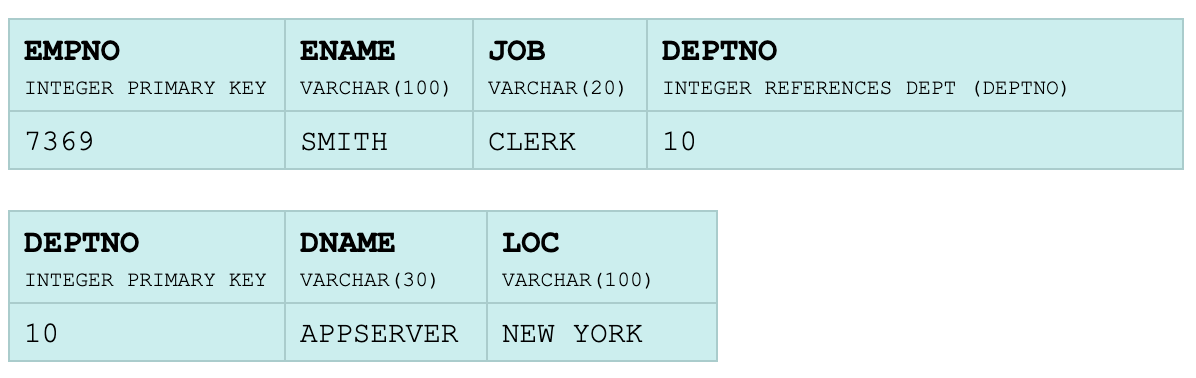
Целевой граф должен правильно связывать сущности из двух таблиц через объектный предикат, использовать заданные URI для предикатов, а также генерировать URI сущностей. Базовое правило может выглядеть так:
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns#>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName "EMP" ];
rr:subjectMap [
rr:template "http://data.example.com/employee/{EMPNO}";
rr:class ex:Employee;
];
rr:predicateObjectMap [
rr:predicate ex:name;
rr:objectMap [ rr:column "ENAME" ];
].
Предикат rr:logicalTable указывает на исходную таблицу, предикат rr:subjectMap создает правило генерации URI, а именно - использовать шаблон http://data.example.com/employee/{EMPNO} , где в {EMPNO} подставляется значение первичного ключа. В дополнение, мы объявляем каждую новую сущность как экземпляр класса ex:Employee. Предикат rr:predicateObjectMap объявляет отображение колонки "ENAME" на предикат ex:name графа, значением предиката будет значение ячейки колонки. Таким образом, первое правило позволит сгенерировать из заданной таблицы два триплета:
<http://data.example.com/employee/7369> rdf:type ex:Employee.
<http://data.example.com/employee/7369> ex:name "SMITH".
Для следующего шага возьмем за источник результат SQL-запроса:
<#DeptTableView> rr:sqlQuery """
SELECT DEPTNO,
DNAME,
LOC,
(SELECT COUNT(*) FROM EMP WHERE EMP.DEPTNO=DEPT.DEPTNO) AS STAFF
FROM DEPT;
""".
Новое правило для генерации новых триплетов на основе результатов заданного выше запроса:
<#TriplesMap2>
rr:logicalTable <#DeptTableView>;
rr:subjectMap [
rr:template "http://data.example.com/department/{DEPTNO}";
rr:class ex:Department;
];
rr:predicateObjectMap [
rr:predicate ex:name;
rr:objectMap [ rr:column "DNAME" ];
];
rr:predicateObjectMap [
rr:predicate ex:location;
rr:objectMap [ rr:column "LOC" ];
];
rr:predicateObjectMap [
rr:predicate ex:staff;
rr:objectMap [ rr:column "STAFF" ];
].
В этом правиле rr:logicalTable ссылается на SQL-запрос и использует его возвращаемые переменные для создания отображений: значение DEPTNO генерирует URI сущности типа ex:Department, колонка DNAME отображается на предикат ex:name, LOC на ex:location, и STAFF как результат агрегирующего запроса на ex:staff. Новое правило сгенерирует четыре триплета:
<http://data.example.com/department/10> rdf:type ex:Department.
<http://data.example.com/department/10> ex:name "APPSERVER".
<http://data.example.com/department/10> ex:location "NEW YORK".
<http://data.example.com/department/10> ex:staff 1.
Связь между таблицами осуществляется через внешние ключи (foreign keys). При отображении в RDF эта связь должна быть объектным предикатом, R2RML позволяет это сделать, добавляя в уже существующий TriplesMap1 новое правило:
<#TriplesMap1>
rr:predicateObjectMap [
rr:predicate ex:department;
rr:objectMap [
rr:parentTriplesMap <#TriplesMap2>;
rr:joinCondition [
rr:child "DEPTNO";
rr:parent "DEPTNO";
];
];
].
В этом правиле создается предикат ex:department, а его значение равно значению операции соединения (join) по колонке DEPTNO в обоих таблицах, причем таблица DEPT указана как rr:parentTriplesMap в условии генерации значения. Новый триплет получится таким:
<http://data.example.com/employee/7369> ex:department <http://data.example.com/department/10>.
Заметим, что субъект и объект предиката - уже сгенерированные сущности с известными URI. Последним шагом создадим отображение колонки JOB на граф с условием генерации новой сущности с другим префиксом и именем general-office:
<#TriplesMap1>
rr:logicalTable [ rr:sqlQuery """
SELECT EMP.*, (CASE JOB
WHEN 'CLERK' THEN 'general-office'
WHEN 'NIGHTGUARD' THEN 'security'
WHEN 'ENGINEER' THEN 'engineering'
END) ROLE FROM EMP
""" ];
rr:subjectMap [
rr:template "http://data.example.com/employee/{EMPNO}";
];
rr:predicateObjectMap [
rr:predicate ex:role;
rr:objectMap [ rr:template "http://data.example.com/roles/{ROLE}" ];
].
Как логическая таблица в правиле указан результат выполнения SQL-запроса, который возвращает переменную ROLE, которая, в свою очередь, используется для генерации URI объекта триплета с указанным предикатом ex:role. Результатом выполнения правила будет триплет
<http://data.example.com/employee/7369> ex:role <http://data.example.com/roles/general-office>.
Больше деталей рекомендации доступно в документации [2]. Существует несколько реализаций процессора R2RML маппингов, как открытые [3], так и коммерческие.
RML
R2RML позволяет преобразовывать содержимое реляционных баз данных. Однако, c распространением NoSQL систем большие объемы данных могут храниться и в других форматах, например, CSV, JSON, XML. Для преобразования этих форматов разработана спецификация RML (RDF Mapping Language) [4], являющаяся надмножеством и расширением R2RML.
RML абстрагируется от понятий, присущих только реляционным базам, и вводит более общие. Отличия приведены ниже:
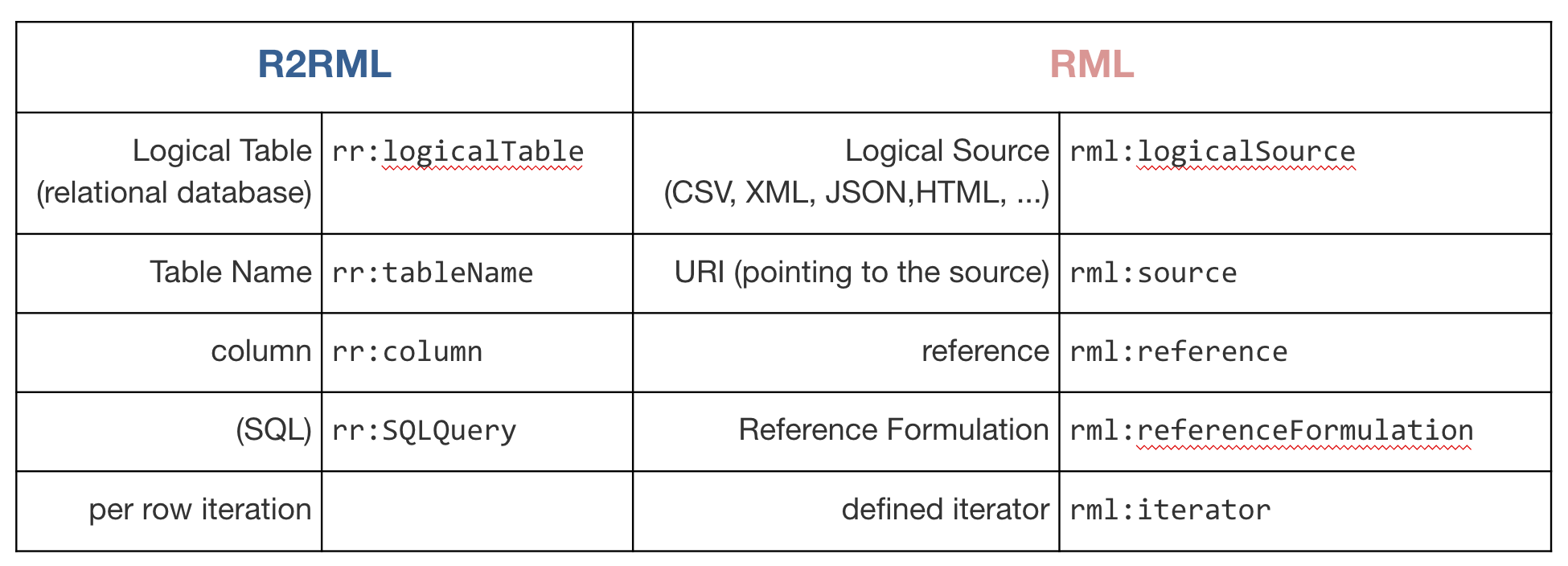
RML позволяет создавать универсальные отображения в синтаксисе Turtle, обеспечивающие преобразование нескольких разнородных источников в один граф. Специфичным для конкретного формата является только способ выбора пары предикат-значение (rml:reference) - так, для XML-источников это будет выражение XPath, для JSON - JSONPath, а для CSV - название колонки.
Например, пусть задан источник в формате CSV
id, stop, latitude, longitude
6523, 25, 50.901389, 4.484444
RML-правило может выглядеть так:
<#Mapping1>
rml:logicalSource [
rml:source "http://www.example.com/airports.csv" ;
rml:referenceFormulation ql:CSV
];
rr:subjectMap [
rr:template "http://airport.example.com/{id}";
rr:class transit:Stop
];
rr:predicateObjectMap [
rr:predicate transit:route;
rr:objectMap [
rml:reference "stop";
rr:datatype xsd:int
]
];
rr:predicateObjectMap [
rr:predicate :lat;
rr:objectMap [
rml:reference "latitude"
]
];
rr:predicateObjectMap [
rr:predicate:long;
rr:objectMap [
rml:reference "longitude"
]
].
Приведенное выше правило сгенерирует четыре триплета на основе файла airports.csv в referenceFormulation как CSV:
<http://airport.example.com/6523> rdf:type transit:Stop .
<http://airport.example.com/6523> transit:route 25 .
<http://airport.example.com/6523> :lat 50.901389 .
<http://airport.example.com/6523> :long 4.484444 .
Пусть задан JSON-источник:
{
"venue":
{
"latitude": "51.0500000",
"longitude": "3.7166700"
},
"location":
{
"continent": " EU",
"country": "BE",
"city": "Brussels"
}
}
RML-отображение может выглядеть так:
<#VenueMapping>
rml:logicalSource [
rml:source "http://www.example.com/files/Venue.json";
rml:referenceFormulation ql:JSONPath;
rml:iterator "$"
];
rr:subjectMap [
rr:template "http://loc.example.com/city/{$.location.city}";
rr:class schema:City
];
rr:predicateObjectMap [
rr:predicate wgs84_pos:lat;
rr:objectMap [
rml:reference "$.venue.latitude"
]
];
rr:predicateObjectMap [
rr:predicate wgs84_pos:long;
rr:objectMap [
rml:reference "$.venue.longitude"
]
];
rr:predicateObjectMap [
rr:predicate gn:countryCode;
rr:objectMap [
rml:reference "$.location.country"
]
].
В этом правиле как источник выбран файл Venue.json, referenceFormulation язык JSONPath, и корневой селектор $. Каждый predicateObjectMap использует корневой селектор для задания искомого значения к определенному предикату. В результате получится четыре триплета:
<http://loc.example.com/city/Brussels> rdf:type schema:City.
<http://loc.example.com/city/Brussels> wgs84_pos:lat "50.901389".
<http://loc.example.com/city/Brussels> wgs84_pos:long "4.484444".
<http://loc.example.com/city/Brussels> gn:countryCode "BE".
Механизм создания объектных предикатов схож с R2RML с поправкой на введение условий операции соединения (join condition) и разные селекторы для разных форматов. Больше деталей доступно в спецификации [4]. В предложенной реализации RML [5] присутствует процессор правил, осуществляющий собственно трансформацию, графический интерфейс создания правил, валидатор правил и онтология сущностей RML.
Инструменты
Перечислим несколько популярных инструментов для преобразования гетерогенных данных в RDF графы помимо стандартных консольных приложений. Karma [6] - платформа для интеграции данных из форматов CSV, XML, JSON и реляционных баз данных. Особое внимание уделено сбору информации с HTML страниц. Одним из преимуществ Karma в удобном графическом интерфейсе, который позволяет создавать отображения не только в текстовом редакторе, но и визуально.
OpenRefine [7] - инструмент для очищения, трансформации и обогащения данных. Основной табличное представление может быть экспортировано с помощью расширений в RDF графы с помощью расширения LODRefine [8].
LinkedPipes [9] - ETL-решение для трансформации данных в RDF. LinkedPipes позволяет создавать многоступенчатые процессы обработки и трансформации (pipelines) в графическом интерфейсе. Клиент-серверная архитектура поддерживает коммуникацию через REST API, а большое количество расширений и компонентов повышает функциональность.
SPARQL Generate [10] - расширение SPARQL 1.1, позволяющее генерировать RDF-графы из гетерогенных источников, опрашивая их через SPARQL, где отображения задаются как функции-итераторы (iterators) и функции-привязки (bindings) над каждым источником. Поддерживает множество форматов источников вплоть до обычного текста, где запрос преобразуется в регулярное выражение, и Web API с потоковой передачей данных.
Федерализация данных (Virtual Integration)
Второй вариант интеграции данных - федеративный - не предполагает конверсии всех исходных источников в единый формат. Тому может быть несколько причин: например, объем данных слишком велик; нет доступа к исходным файлам, а только через некоторую точку доступа; данные и источники часто изменяются, и преобразование не выгодно. В таком случае прибегают к виртуальной интеграции, предполагающей создание единой логической схемы с единым языком запросов (например, онтологии и SPARQL), и популяция графа знаний может проводиться путем модификации и переписывания запросов в стандартные формате опрашиваемых источников.
Mediator-Wrapper Architecture
Классической архитектурой сценария виртуальной интеграции является “медиатор-оболочка” (mediator-wrapper) [11], изображенная ниже
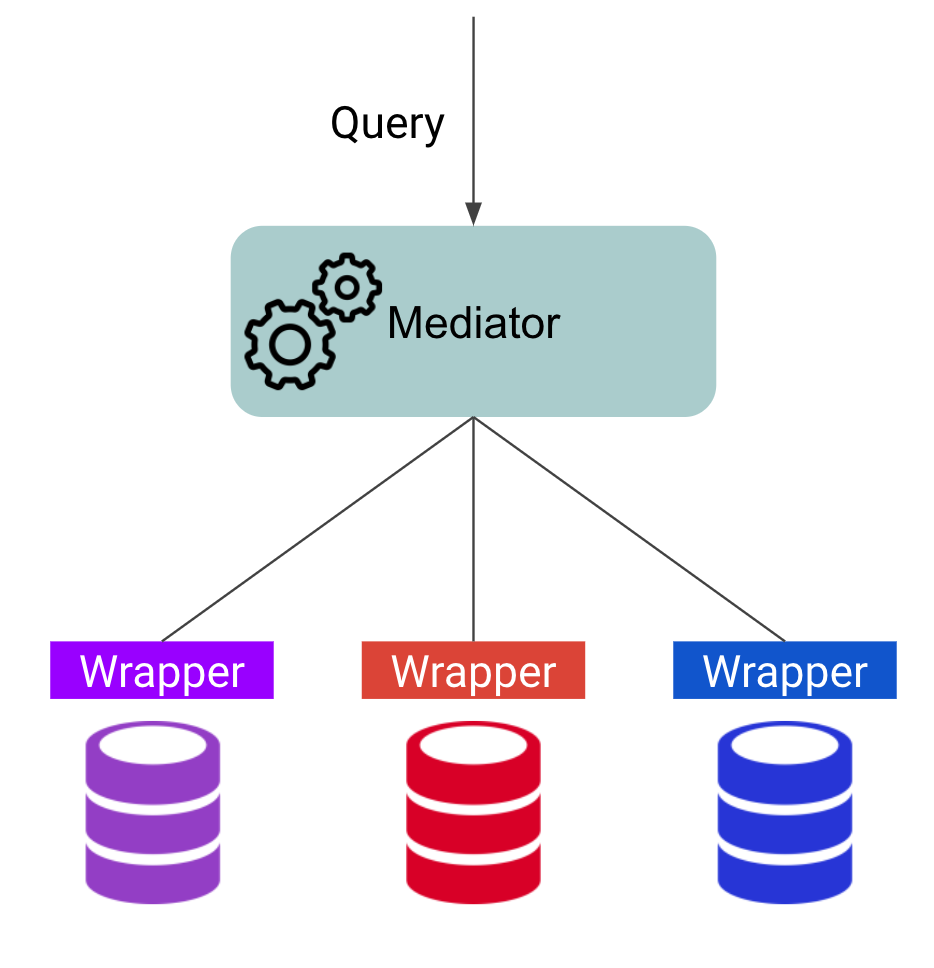 Архитектура медиатор-оболочка
Архитектура медиатор-оболочка
К задачам медиатора (mediator) относится обработка и разбиение оригинального запроса на подзапросы, каждый из которых отправится к соответствующему источнику. Определение нужного источника производится в соответствии с отображениями (маппингами). При этом медиатор обязан ответить на запрос в том же формате, в котором пришел запрос - иными словами, медиатор должен преобразовывать ответы от источников в единый формат. Таким образом, медиатор скрывает различия источников и представляет их как единое целое логически. Эффективность работы медиатора также зависит от его способности оптимизировать запрос и создавать планы исполнения, учитывающие специфику источников.
Оболочка (wrapper, worker) - программный компонент над некоторым источником, способный выполнять запросы к этому источнику и получать от него результаты. Оболочки, как правило, работают уже с уникальной схемой источника, и передают результаты на уровень вверх медиатору.
Виртуальная интеграция предполагает хранение или доступ источников в их оригинальных форматах без преобразований в единый формат. Если в сценарии физической интеграции применялись ETL-инструменты и решения класса Data Warehouse, то в сценарии виртуальной интеграции уровень хранения называют Data Lake. Данные в Data Lake могут свободно загружаться и удаляться без подготовленной заранее схемы этих данных. Таким образом, это задача медиатора (или похожих систем виртуальной интеграции) выделить схему, связать ее с единым логическим представлением и подключить к процессам оптимизации и исполнения запросов.
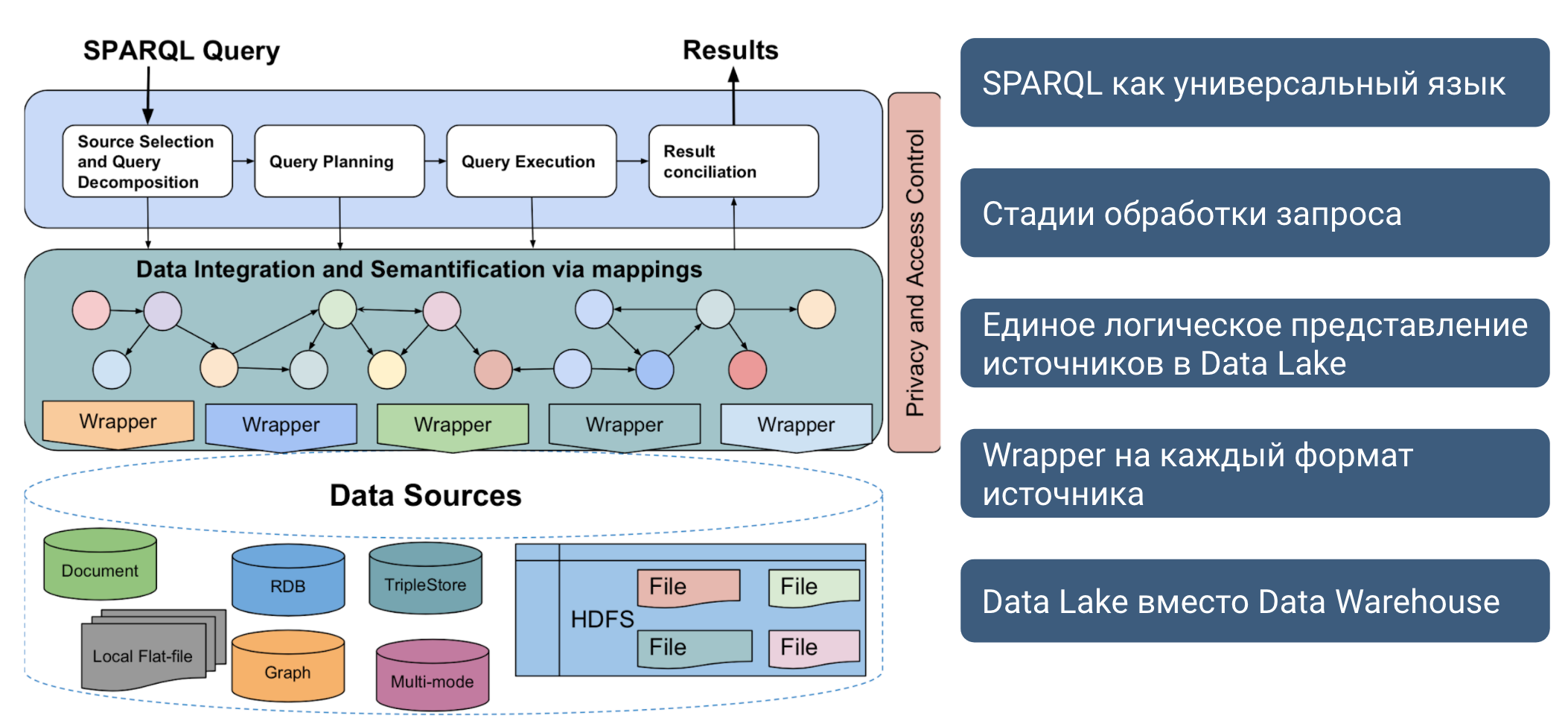 Схема виртуальной интеграции с Data Lake [12]
Схема виртуальной интеграции с Data Lake [12]
Рисунок иллюстрирует схему виртуальной интеграции c медиатором, оболочками над каждым источником, и Data Lake, где эти источники находятся, при этом источники могут физически находится в разных местах и вычислительных пространствах. Часто на уровень между медиатором и оболочкой помещают мета-оболочки (meta-wrapper), которые выполняют собственно переписывание запроса к целевому источнику на основании плана от медиатора. Дополнительно, мета-оболочки могут заниматься и преобразованием полученных ответов к единой схеме, понимаемой медиатором. Ниже мы рассмотрим основные компоненты этой архитектуры.
Федеративные запросы в RDF (Federated querying)
Сценарий виртуальной интеграции и архитектура “медиатор-оболочка” на практике часто реализуется через федеративные платформы обработки запросов. В области семантической интеграции распространение получили федеративные обработчики, работающие со SPARQL-запросами. Источниками могут быть как RDF-графы разных моделей, так и не-RDF форматы. К задачам медиатора относится разбиение запроса и выбор релевантных источников (Query Decomposition and Source Selection), планирование запроса (Query Planning), исполнение запроса (Query Execution), и объединение результатов (Results Reconciliation). Оболочки, в свою очередь, обязаны опрашивать прикрепленные источники и на выходе отдавать пригодные для SPARQL-движков данные.
Query Decomposition & Source Selection
Data Lake и федеративная платформа обработки запросов с помощью отображений и онтологий инкапсулируют гетерогенные источники в один логический граф знаний. При обработке запроса нужно решить обратную задачу и найти конкретные источники, способные обработать части запроса. На первой стадии исходный запрос разбивается (например, по триплетам) и анализируется с помощью статистики об источниках на предмет нахождения триплета в источнике и полноты информации.
 Исходный запрос разбивается на три триплета анализируется на предмет нахождения в трех источниках.
Исходный запрос разбивается на три триплета анализируется на предмет нахождения в трех источниках.
Запрос может быть разбит на три триплета, тогда как каждый источник может ответить на два, причем для получения полной информации нужно комбинировать источники или определить, являются ли данные одного источника подмножеством другого. От правильной декомпозиции запроса и выбора релевантных источников зависит полнота результатов (движок вернет все возможные результаты) и время выполнения запроса.
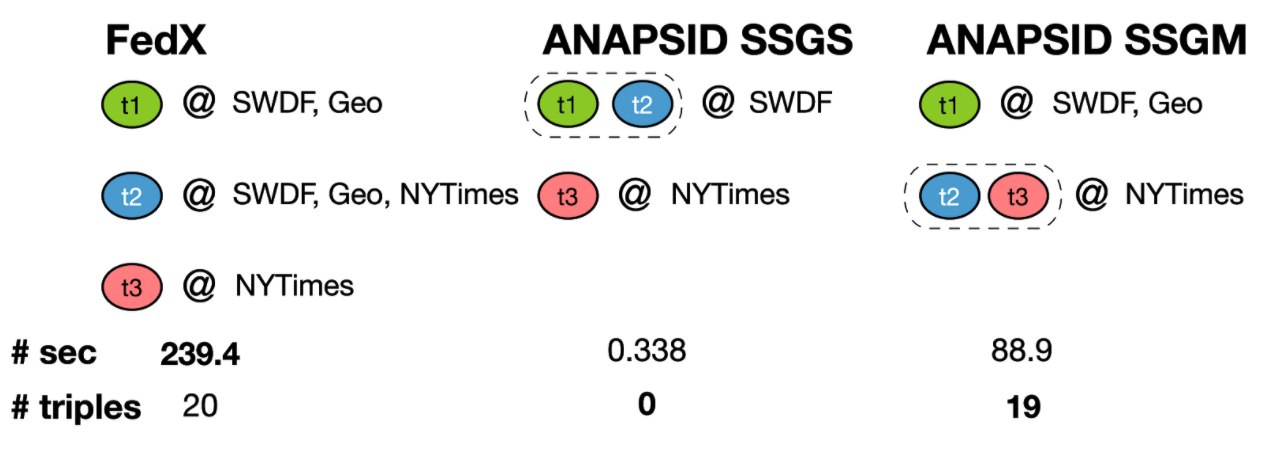 Варианты декомпозиции и выбора источников двумя системами и результаты
Варианты декомпозиции и выбора источников двумя системами и результаты
На схеме приведен пример декомпозиции запроса двумя федеративными SPARQL-движками FedX [13] и ANAPSID [14] . FedX разбивает запрос на триплеты, и отправляет каждый во все источники, которые согласно статистике могут содержать триплеты подобного шаблона. Такая стратегия возвращает все возможные результаты (20) ценой большого времени выполнения (порядка 240 секунд). ANAPSID может использовать две стратегии-эвристики, первая отправит два шаблона только к одному источнику, что приведет к отсутствию результатов, Вторая стратегия отправит первый шаблон к двум источникам, а два других к третьему, что приведет к почти полным результатам (19 вместо 20 у FedX) за счет значительного выигрыша в скорости обработки (порядка 90 секунд против 240 у FedX).
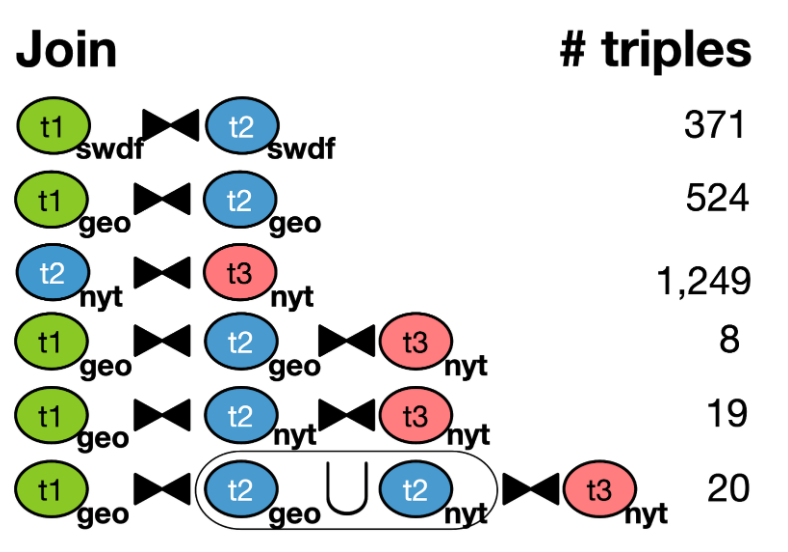 Пример статистики операций соединения по триплетам и источникам
Пример статистики операций соединения по триплетам и источникам
Как медиатор выбирает источники? Как правило, платформы собирают статистику о содержимом доступных источников и их комбинациях, например, подсчитывают количество результатов операции соединения (join) по каждому триплету в нескольких источниках как показано на рисунке. Более продвинутые системы [15] производят декомпозицию по группам триплетов, объединенных общим классом и, соответственно, собирают дополнительные параметры по классам в источниках и их комбинациям.
Результатом работы компонента является набор более простых запросов с указанным источником, например, с использованием ключевого слова SERVICE на SPARQL 1.1:
SELECT ?s WHERE {
SERVICE <wrapper_address> {
?s foaf:page ?page .
}
}
Query Planning
Как только определены опрашиваемые источники и запрос переписан в набор более простых, стадия планирования определяет оптимальную последовательность выполнения этих запросов и операций соединения их промежуточных результатов. Как правило, план выглядит как дерево - бинарное в случае использования бинарных соединений (binary joins) или n-арное в случае многомерных соединений (multi-way joins). Медиатор опирается на эвристики и статистику об источниках, чтобы выбрать подходящие операторы соединения и их порядок.
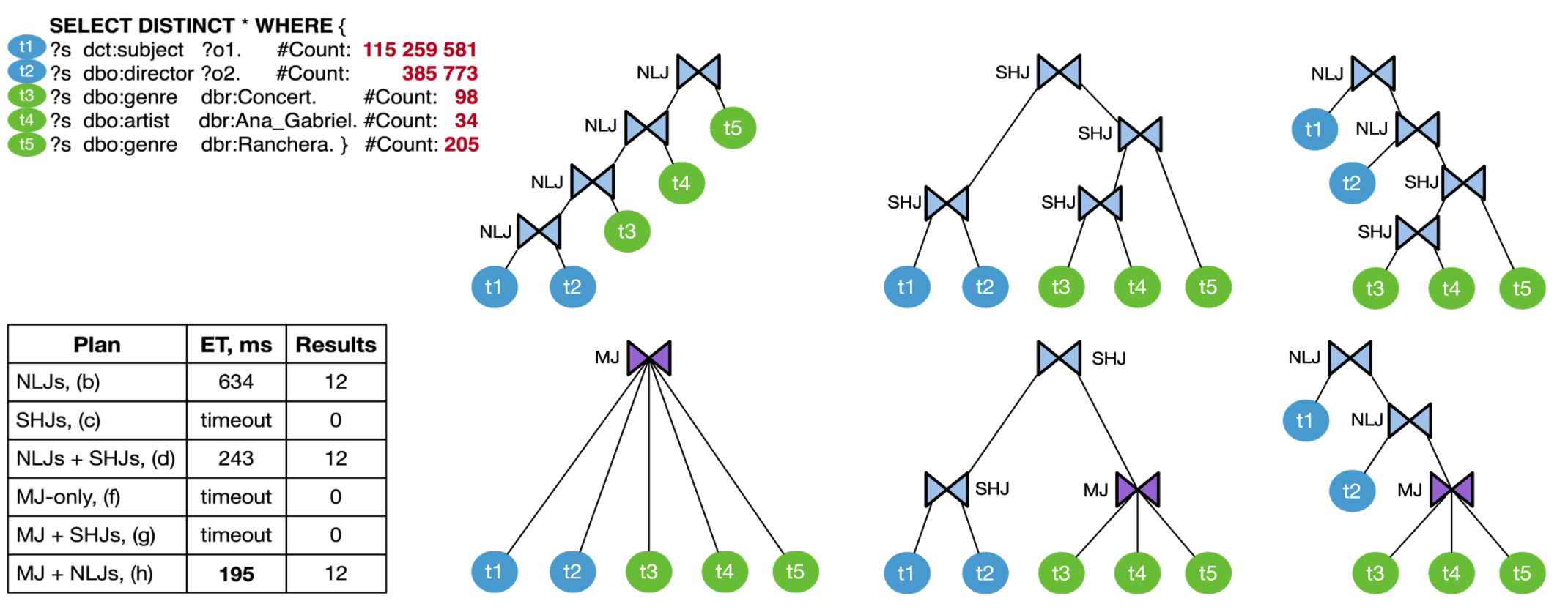 Возможные планы исполнения запроса
Возможные планы исполнения запроса
Рисунок иллюстрирует возможные варианты плана запроса. Например, дерево из вложенных соединений (nested loop joins) медиатор получил из статистики о количестве триплетов каждого шаблона (selectivity) - в данном запросе это количество сильно разнится: от 34 результатов до сотен миллионов. В этом плане сначала выполняется соединение самых многочисленных шаблонов, и затем промежуточные результаты соединяются с малочисленными. Это пример не до конца оптимизированного запроса, который, однако, выполняется и возвращает результаты.
Второй план из симметричных соединений (symmetric hash join) использует другой тип операторов соединения в другом порядке, когда высоко- и мало-селективные шаблоны соединяются параллельно, и только на следующих уровнях их промежуточные результаты соединяются в финальный ответ. Это пример неоптимизированного плана, так как симметричные операторы должны обработать миллионы комбинаций, и порядки обрабатываемых триплетов левой и правой части дерева не сбалансированы. Такой план будет исполняться в сотни раз дольше остальных и потому не вернет результаты в разумное время.
Наконец, третий план из комбинации симметричных и вложенных операторов - наиболее оптимизированный из трех, так как высоко-селективные шаблоны соединяются первыми, а промежуточные результаты отправляются во вложенные операторы, что исключает необходимость обработки сотен миллионов результатов мало-селективных шаблонов. Такой план исполнится быстрее остальных и вернет то же самое количество финальных результатов, что и первый.
Более того, можно перейти от использования только бинарных операторов соединений к n-арным (multi-way joins). Правильное использование таких операторов может сэкономить еще 10-20% времени исполнения запроса.
Query Execution
Как только построен оптимальный по оценке медиатора план, запросы отправляются к выбранным источникам - их оболочкам (wrappers). Федеративные платформы часто настраивают так, чтобы результаты поступали по мере их обработки планировщиком в кумулятивной манере. Другими словами, результаты возвращаются не все сразу после завершения обработки всех подзапросов, а продолжительно во времени, что эффективно при обработке больших запросов. Однако, на этапе исполнения могут возникнуть сложности с доступностью источников или высокими сетевыми задержками. В этом случае медиатор должен быть адаптивным и динамически изменять план запроса в реальном времени.
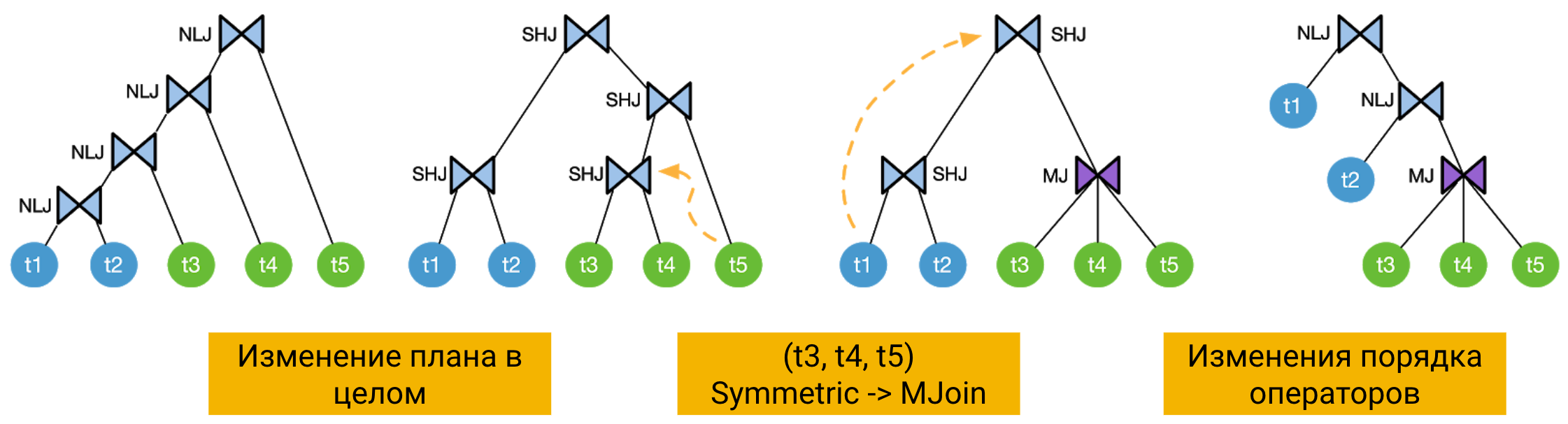 Адаптивное изменения плана запроса
Адаптивное изменения плана запроса
Например, рисунок выше иллюстрирует динамическое изменение плана - выполнение изначально заданного столкнулось с трудностями, и два бинарных симметричных оператора объединены в один n-арный. Затем, исполнение левой части дерева может нарушиться, и медиатор перестраивает последовательность, помещая проблемный источник на самое последнее промежуточное место, изменяя операторы с симметричных на вложенные.
Results Reconciliation
Как правило, результат выполнения запроса - небольшой RDF-граф. Перед отправкой готового результата медиатор может выполнять дополнительное агрегирование и объединение результатов. Например, на стадии агрегирования семантически похожие графы (другими словами, описывающие одну и ту же сущность реального мира) можно объединить, уменьшив дупликацию результатов.
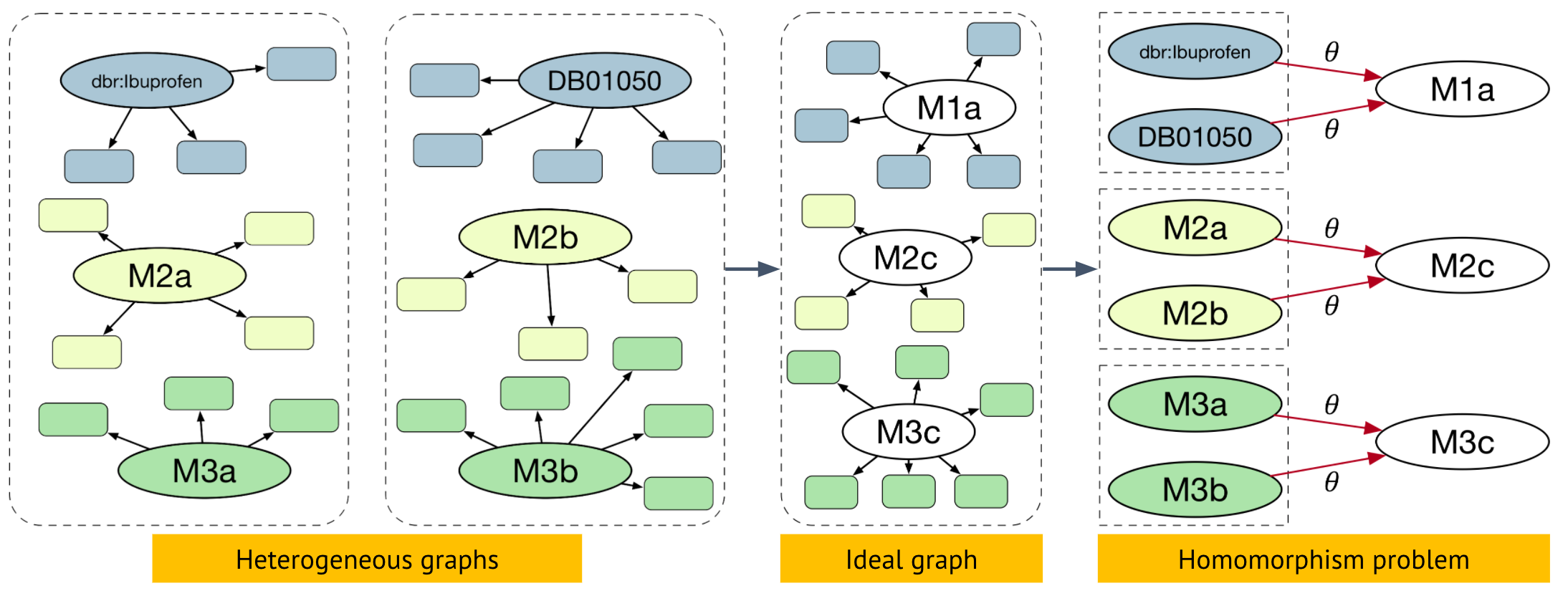 Задача entity matching
Задача entity matching
Такая задача называется entity matching, и в последнее время быстрые и эффективные подходы используют графовые нейронные сети, о чем мы поговорим в следующих лекциях.
Wrappers
Оболочки (wrappers) привязаны к каждому источнику. На вход оболочка получает часть переписанного запроса от медиатора, а на выходе отдает результаты от источника. Основная задача оболочки - переписать запрос от медиатора в формат, поддерживаемый источником, и преобразовать оригинальные результаты в схему, принимаемую медиатором. В федеративных RDF платформах единым языком является SPARQL, соответственно, оболочки должны переписывать SPARQL в целевой формат источника (SQL, XML, CSV, JSON, и тд), и преобразовывать вывод источника в SPARQL-совместимый. На этом этапе, как правило, и возникают основные трудности, т.к. выразительность SPARQL часто шире выразительности целевого языка.
Оболочки должны учитывать тип источника и среду выполнения запроса к этому источнику. Например, оболочки над реляционными БД используют SQL как язык целевого запроса, подразумевая, что SQL-запрос исполнится соответствующей СУБД. Форматы типа XML, CSV, JSON имеют соответствующие языки запросов, но среда выполнения может различаться - например, они могут храниться как простые файлы (flat files) в распределенной системе Hadoop или как RDD в Apache Spark.
SPARQL to SQL, OnTop
Один из самых используемых типов оболочек преобразовывает SPARQL-запрос в SQL-запрос. Большинство данных (особенно корпоративных) по-прежнему хранится в реляционных СУБД, и физическая трансформация их содержимого в RDF может быть по разным причинам не оправдана. Тогда реляционную СУБД (или любую СУБД, обрабатывающую SQL-запросы) подключают к оболочке, транслирующей на лету SPARQL в SQL. Одной из таких оболочек является Ontop [16].
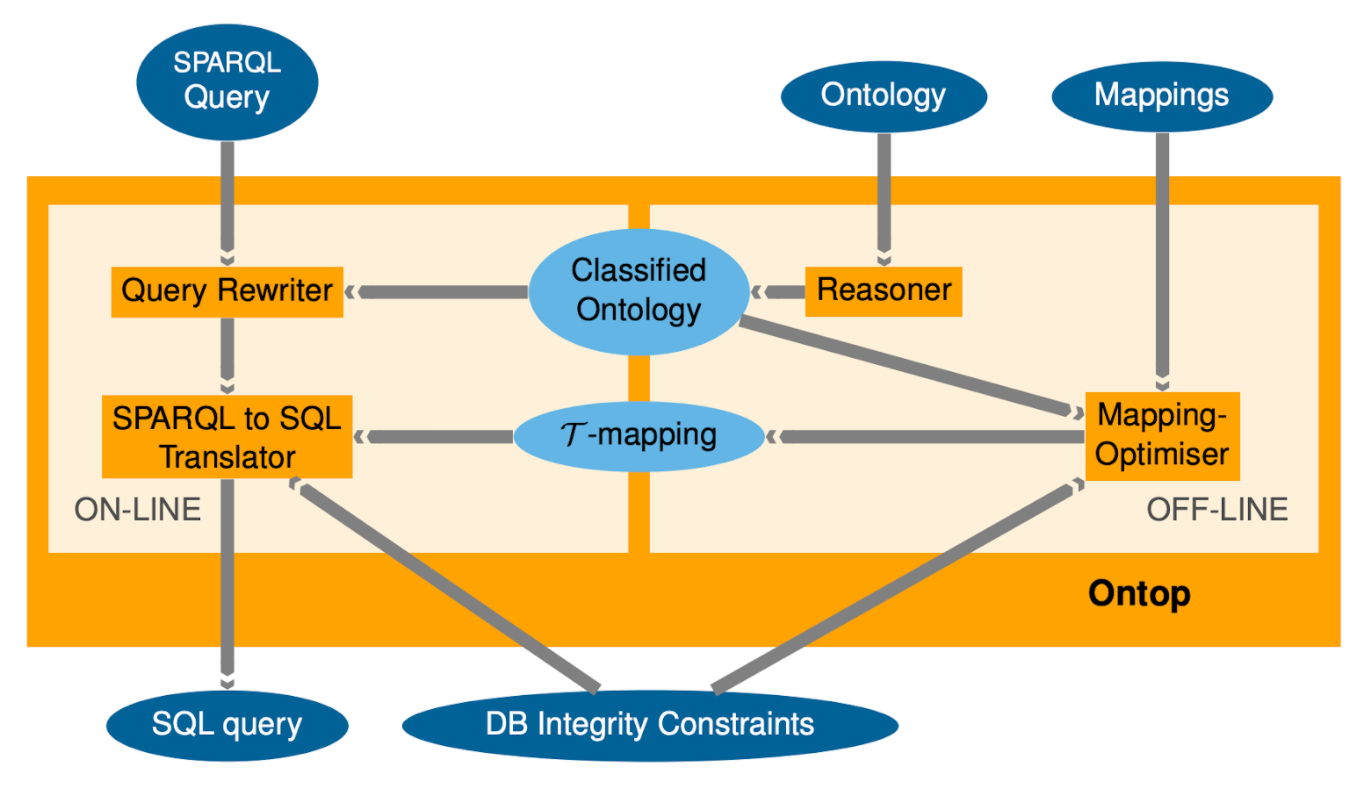 Процесс обработки SPARQL запроса в SQL в Ontop [16]
Процесс обработки SPARQL запроса в SQL в Ontop [16]
На вход помимо SPARQL-запроса поступает OWL онтология (профиля OWL 2 QL), отображения (маппинги на языке Quest или R2RML), а также схема реляционной БД, к которой будет отправлен переписанный запрос. Концептуально, процесс состоит из двух ступеней:
- Подготовительный этап (off-line), когда после загрузки онтологии, схемы реляционной базы и маппингов Ontop использует встроенную машину логического вывода (reasoner) для составления 𝝉-mappings, внутреннего представления правил, оптимизированного для оптимизации запросов
- Исполнительный этап (on-line), когда на вход подается уже сам SPARQL-запрос. SPARQL-запрос преобразуется в дерево, где узлы - операторы (JOIN, OPTIONAL, UNION, FILTER, PROJECT), а листья - шаблоны триплетов (triple patterns). В базовой версии дерева начальная версия SQL запроса может получиться неоптимальной. Поэтому затем дерево оптимизируется в соответствии с построенными 𝝉-mappings и создаются усовершенствованные запросы. Полученный SQL-запрос выполняется через JDBC на целевом источнике, а полученные результаты транслируются в RDF.
Например, пусть задан исходный SPARQL-запрос:
SELECT ?tumor WHERE {
?tumor rdf:type :Neoplasm ;
:hasStage :stage-IIIa .
}
Сгенерированный напрямую SQL-запрос без оптимизаций может выглядеть так:
SELECT Q1.x FROM
(( SELECT concat(“:db1/neoplasm/”, pid) AS x FROM tbl_patient
WHERE type=false OR type=true) Q1
JOIN
( SELECT concat(“:db1/neoplasm/”, pid) AS x FROM tbl_patient
WHERE stage = 4 ) Q2
ON
Q1.x = Q2.x )
Усовершенствованный запрос после первой стадии структурных оптимизаций:
SELECT concat(“:db1/neoplasm/”, Q.pid) AS x FROM
(SELECT T1.pid
FROM tbl_patient T1 JOIN tbl_patient T2 ON T1.pid = T2.pid
WHERE (T1.type = false OR T1.type = true) AND T2.stage = 4
) Q
После удаления избыточных self-joins запрос усовершенствуется далее:
SELECT concat(“:db1/neoplasm/”, Q.pid) AS x FROM
(SELECT pid FROM tbl_patient
WHERE (type=false OR type=true) AND stage = 4) Q
Наконец, еще одна стадия структурных оптимизаций приводит к финальному виду целевого запроса:
SELECT concat(“:db1/neoplasm/”, pid) AS x
FROM tbl_patient
WHERE (type=false OR type=true) AND stage = 4
Домашнее задание
Потренируйтесь использовать правила и парсер RML, чтобы преобразовать в RDF несколько датасетов с Kaggle:
- Netflix Shows (исходный формат CSV) - как базовую онтологию используйте schema.org, а для генерации URI колонку
show_id. Для маппинга TV Shows используйте schema:TVSeries и релевантные предикаты, для Movie - schema:Movie. - Amazon Music Reviews (исходный формат JSON) - используйте schema:Review как основной класс и используйте релевантные для него предикаты. Для генерации URI используйте конкатенацию
reviewerIDиasin, напримерhttp://example.com/{reviewerID}/{asin}.
Для создания URIs, которых нет в schema.org, используйте префикс http://example.com/
Использованные материалы и ссылки:
[0] Maurizio Lenzerini. Data Integration: A Theoretical Perspective. PODS 2002 paper
[1] Georg Gottlob, Stanislav Kikot, Roman Kontchakov, Vladimir V. Podolskii, Thomas Schwentick, Michael Zakharyaschev. The price of query rewriting in ontology-based data access. Artif. Intell. 213: 42-59 (2014) paper
[2] https://www.w3.org/2001/sw/rdb2rdf/r2rml/
[3] https://www.w3.org/TR/rdb2rdf-implementations/
[4] http://rml.io/spec.html
[5] http://rml.io/RMLsoftware.html
[6] https://github.com/usc-isi-i2/Web-Karma
[7] http://openrefine.org/
[8] https://github.com/sparkica/LODRefine
[9] https://etl.linkedpipes.com/
[10] Maxime Lefrançois, Antoine Zimmermann, Noorani Bakerally. A SPARQL extension for generating RDF from heterogeneous formats. In Proc. Extended Semantic Web Conference, ESWC, May 2017 paper
[11] Gio Wiederhold. Mediators in the Architecture of Future Information Systems. IEEE Computer 25(3): 38-49 (1992) paper
[12] Kemele M. Endris, Philipp D. Rohde, Maria-Esther Vidal, Sören Auer. Ontario: Federated Query Processing against a Semantic Data Lake. DEXA 2019. paper
[13] A. Schwarte, P. Haase, K. Hose, R. Schenkel, and M. Schmidt. FedX: Optimization Tech- niques for Federated Query Processing on Linked Data. In ISWC, 2011. paper
[14] M. Acosta, M.-E. Vidal, T. Lampo, J. Castillo, and E. Ruckhaus. ANAPSID: an adaptive query processing engine for SPARQL endpoints. In ISWC, 2011. paper
[15] K. M. Endris, M. Galkin, I. Lytra, M. N. Mami, M.-E. Vidal, and S. Auer. Querying interlinked data by bridging RDF molecule templates. TLDKS, 39:1–42, 2018. paper
[16] Diego Calvanese, Benjamin Cogrel, Sarah Komla-Ebri, Roman Kontchakov, Davide Lanti, Martin Rezk, Mariano Rodriguez-Muro, and Guohui Xiao. Ontop: Answering SPARQL Queries over Relational Databases. Semantic Web Journal. 2017 paper