Лекция 4
Реификация, Wikidata, Валидация
| Материалы | Ссылка |
|---|---|
| Видео | YouTube |
| Слайды | |
| Конспект | здесь |
| Домашнее задание | link |
Видео
Реификация (Reification)
В этой лекции мы уделим особое внимание обеспечению однородности представления знаний в графах при реификации, различные подходы к реификации, а также стандарты валидации знаний в RDF-графах SHACL и ShEx.
Trust & Provenance
Зачем нам нужно задумываться о достоверности содержимого графа? Допустим, у нас есть утверждение “Население Москвы составляет 12 615 882 человека”. Однако, сразу возникают вопросы:
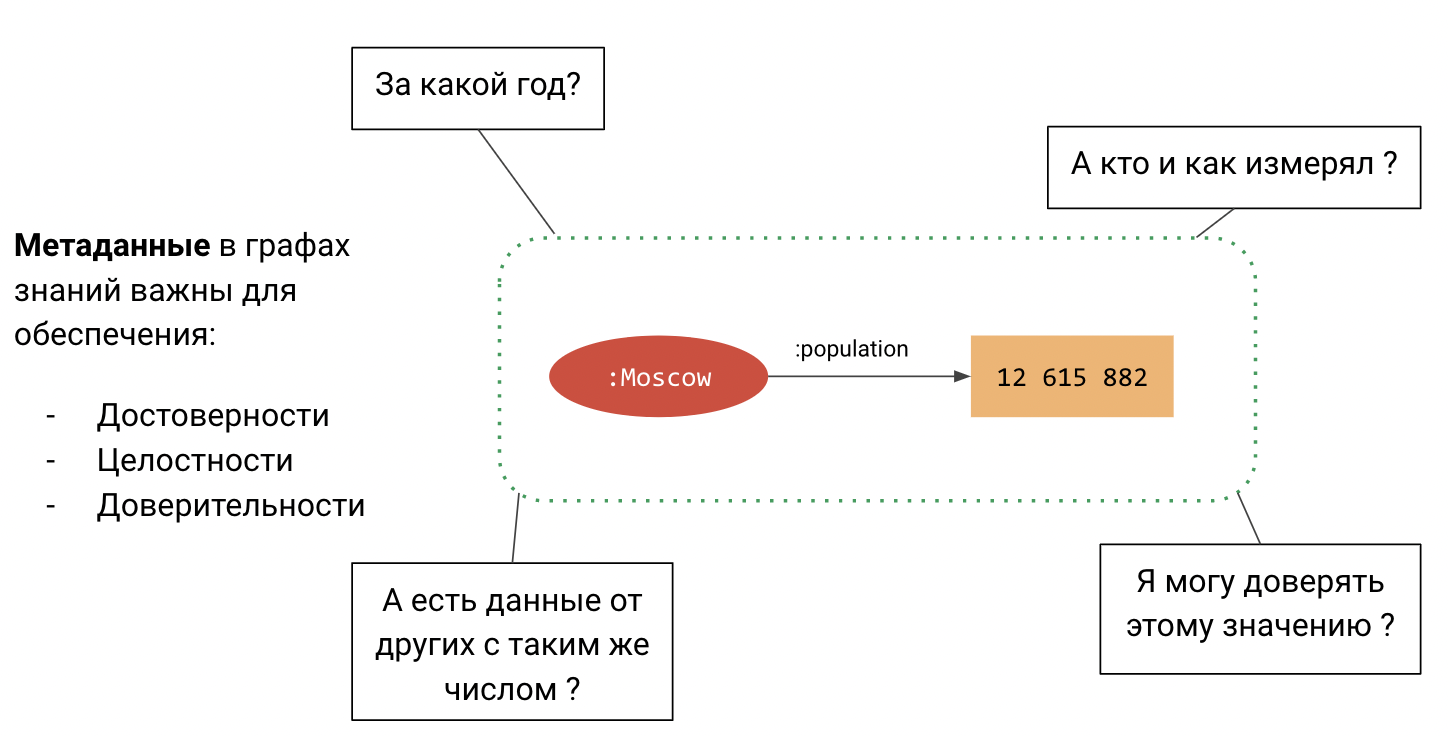
Например,
- Кто и как измерял?
- За какой год это значение?
- Есть ли другие источники с таким же числом?
- Можно ли доверять этому значению?
С ростом графа такие вопросы неизбежно появляются и их необходимо решать для обеспечения общей консистентности содержимого. Для этого нам нужен механизм задания мета-данных об утверждениях. Естественным способом задания таких мета-данных являются атрибуты на гранях графа.
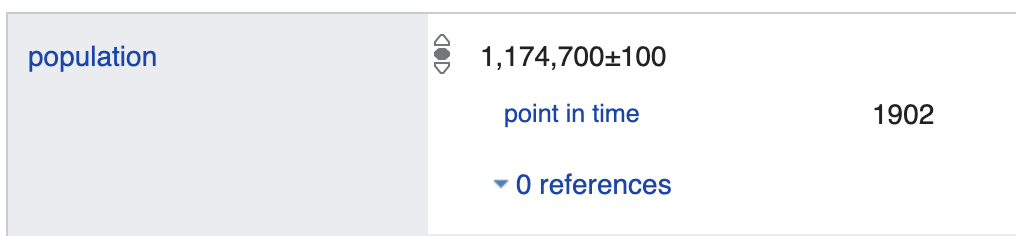
Из прошлой лекции мы узнали, что представление графа в RDF (в отличие от LPG) имеет ограничения на задание атрибутов предикатов. Однако, эти атрибуты могут содержать как специфические данные, например, “Население Москвы составляло 1 174 700 человек на 1902 год ”, так и метаданные и ссылки на источники (provenance), например, “Население Москвы составляло 12 615 882 человека по данным Росстата на 1 января 2019 года”. Например, в графе Wikidata эти факты представляются следующим образом:
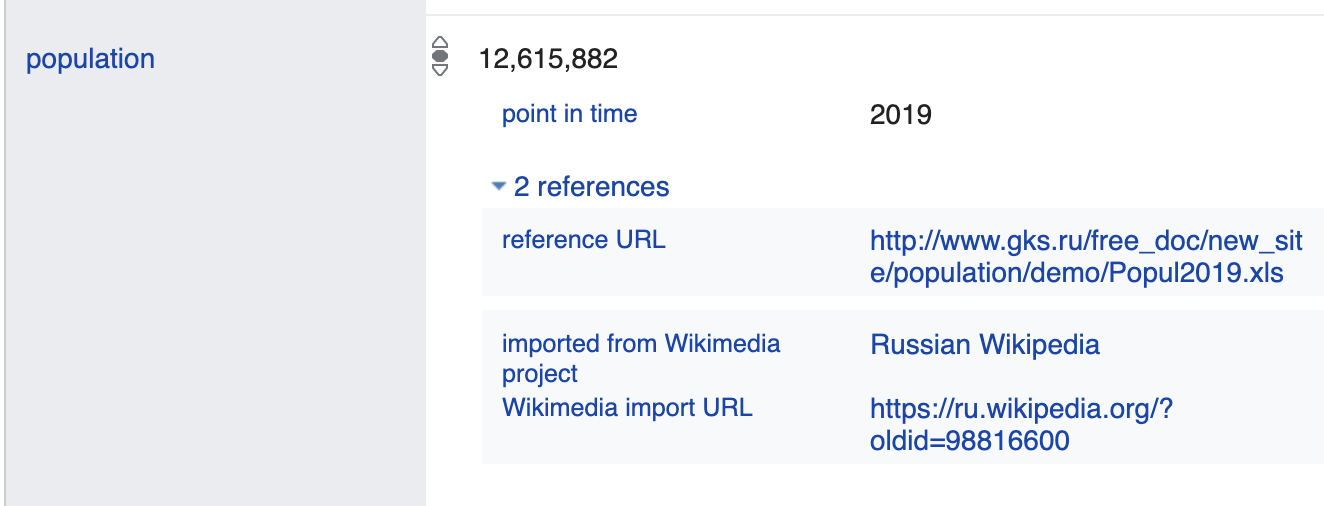
В обоих случаях предикат population детализируется дополнительными значениями. В общем случае предикат может иметь неограниченное число собственных атрибутов.
Моделировать подобные утверждения в RDF позволяет техника реификации (reification). Под реификацией некоторого высказывания понимается описание этого высказывания (триплета) с помощью других триплетов специального формата. Со стороны логики реификация ведет в сторону логик высших порядков, так как позволяет создавать высказывания о высказываниях. В области моделирования и создания RDF графов существует несколько разновидностей реификации, которые мы рассмотрим ниже.
Стандартная RDF реификация
В стандарте RDF для реификации предусмотрен новый класс rdf:Statement и предикаты rdf:subject, rdf:predicate, rdf:object. С их помощью в графе создается новая сущность (вершина) класса rdf:Statement, содержащая ссылки на субъект, предикат и объект триплета через rdf:subject, rdf:predicate, rdf:object, соответственно. В дополнение, к новой вершине можно прикреплять новые атрибуты:
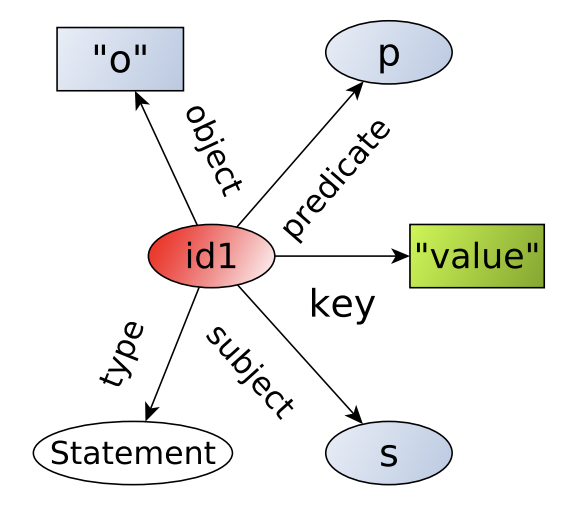 Схема стандартной реификации RDF. Иллюстрация из [1].
Схема стандартной реификации RDF. Иллюстрация из [1].
Например, высказывание “Население Москвы составляло 1 174 700 человек на 1902 год” с помощью стандартной схемы реификации будет выглядеть следующим образом:
<statementID> a rdf:Statement ;
rdf:subject dbr:Moscow;
rdf:predicate dbo:population;
rdf:object 1174700;
dbo:year 1902 .
Обратим внимание, что детализация высказывания о населении, а именно “1902 год”, прикреплена к <statementID>, а не к предикату dbo:population. Стоит заметить, что по семантике стандарта RDF объявление высказывания (statement) о триплете не объявляет существование триплета
dbr:Moscow dbo:population 1174700 .
Замечание справедливо и для остальных схем реификации. Таким образом, при составлении SPARQL-запросов следует иметь в виду, что запрос
SELECT ?population WHERE {
dbr:Moscow dbo:population ?population }
вернет пустое значение, т.к. в явном виде триплет (и соответствующий ему шаблон) в графе не существует. Корректный запрос должен содержать шаблоны rdf:subject, rdf:predicate, rdf:object:
SELECT ?population WHERE {
?statement rdf:subject dbr:Moscow ;
rdf:predicate dbo:population ;
rdf:object ?population . }
В общем случае при реификации явное объявлении триплета dbr:Moscow dbo:population 1174700 может привести к логическим ошибкам. Например, если нужно смоделировать два высказывания о населении Москвы в 1902 и 2019 годах, то триплеты без реификации обозначат, что у Москвы два значения населения без конкретных деталей, и при запросе вернутся оба значения:
dbr:Moscow dbo:population 1174700 .
dbr:Moscow dbo:population 12615882 .
При реификации, однако, каждому высказыванию можно назначить дату через dbo:year:
<statementID2> a rdf:Statement ;
rdf:subject dbr:Moscow;
rdf:predicate dbo:population;
rdf:object 12615882;
dbo:year 2019 .
<statementID1> a rdf:Statement ;
rdf:subject dbr:Moscow;
rdf:predicate dbo:population;
rdf:object 1174700;
dbo:year 1902 .
И в запросах уже указывать конкретный год или получать отсортированную таблицу по годам и значению населения:
SELECT ?population ?year WHERE {
?statement rdf:subject dbr:Moscow ;
rdf:predicate dbo:population ;
rdf:object ?population ;
dbo:year ?year . }
ORDER BY ASC (?year)
К практическим сложностям при реификации также относят:
- Работу с “текущими” или наиболее актуальными значениями. Другими словами, как смоделировать и получать без сложных агрегирующих запросов актуальное значение предиката. Например, по запросу о населении Москвы возвращать значение за 2019 год (или еще более новое) вместо значения за 1902 год.
- Физический объем графа быстро растет - вместо одного триплета необходимо минимум четыре или, как правило, больше триплетов с дополнительными атрибутами. В дополнение, в граф вводятся искусственные новые вершины-высказывания (statements), которые не содержат каких-то знаний.
Именованные графы (Named graphs)
Любой SPARQL endpoint стандарта 1.1 поддерживает понятие именованного графа. Как мы уже знаем, именованный граф - некоторая коллекция триплетов, объединенная одним уникальным идентификатором (IRI). В этом случае детализирующие триплеты принадлежат идентификатору именованного графа:
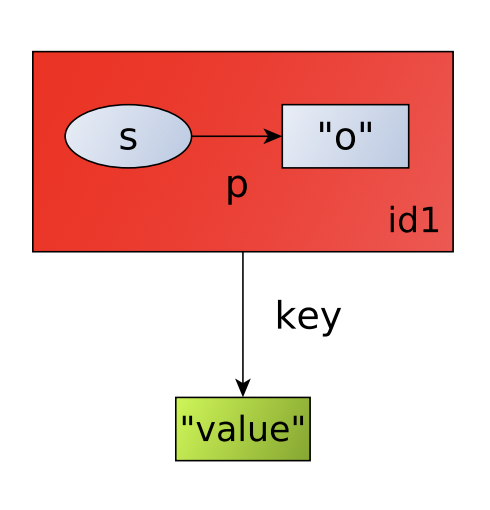 Схема реификации через именованные графы. Иллюстрация из [1].
Схема реификации через именованные графы. Иллюстрация из [1].
Для примера выше такая схема реификации будет предполагать создание двух именованных графов
<graph1> { dbr:Moscow dbo:population 1174700 . }
<graph2> { dbr:Moscow dbo:population 12615882 . }
<graph1> dbo:year 1902 .
<graph2> dbo:year 2019 .
SPARQL-запрос будет выглядеть следующим образом:
SELECT ?population ?year WHERE {
GRAPH ?g { dbr:Moscow dbo:population ?population } .
?g dbo:year ?year .
} ORDER BY ASC (?year)
К преимуществам такого подхода можно отнести простоту внедрения - именованные графы являются частью стандарта, а также экономию места - один новый триплет к идентификатору графа без введения новых вершин в графе. Недостатком является невозможность работы с графами, которые в своей логической модели уже активно опираются на именованные графы для структуризации содержимого.
N-арные предикаты (N-ary predicates)
В этой схеме реификации объект триплета заменяется новой вершиной, которая содержит оригинальное значение (но с искусственно созданным предикатом) и дополнительные триплеты:
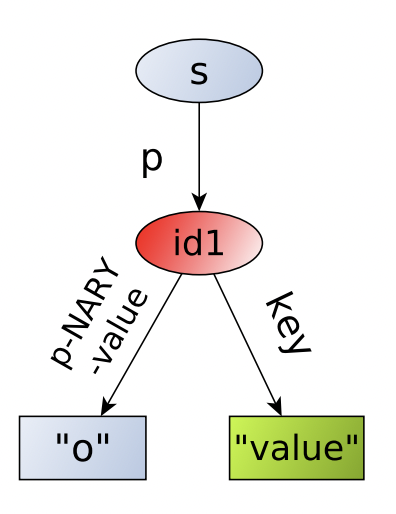 Схема реификации через n-арные предикаты. Иллюстрация из [1].
Схема реификации через n-арные предикаты. Иллюстрация из [1].
Для примера выше такая схема реификации будет предполагать создание двух новых вершин и искусственного предиката, например, dbo:population-value:
dbr:Moscow dbo:population <node1> .
<node1> dbo:population-value 1174700 .
<node1> dbo:year 1902 .
dbr:Moscow dbo:population <node2> .
<node2> dbo:population-value 12615882 .
<node2> dbo:year 2019 .
SPARQL-запрос для такой схемы будет выглядеть следующим образом:
SELECT ?population ?year WHERE {
dbr:Moscow dbo:population ?temp .
?temp dbo:population-value ?population .
?temp dbo:year ?year .}
ORDER BY ASC (?year)
К преимуществам этого подхода можно отнести экономию места - вводится только один новый триплет, к тому же есть возможность работать с именованными графами. Недостатки, однако, связаны с введением новых вершин и предикатов, которые могут нарушить однородность исходной онтологии, в соответствии с которой строился изначальный граф. Так, литеральное свойство dbo:population, имеющее область значений в виде положительных целых чисел, при такой схеме становится объектным свойством. При внедрении данного механизма реификации нужно учитывать эти детали при разработке логической схемы графа (онтологии).
Синглтон-предикаты (Singleton property)
По аналогии с паттерном программирования, в схеме реификации с синглтон-предикатами для каждого высказывания создается уникальный предикат с собственным идентификатором. Уникальный предикат содержит ссылку на исходный предикат с помощью специального свойства rdf:singletonPropertyOf и дополнительные триплеты:
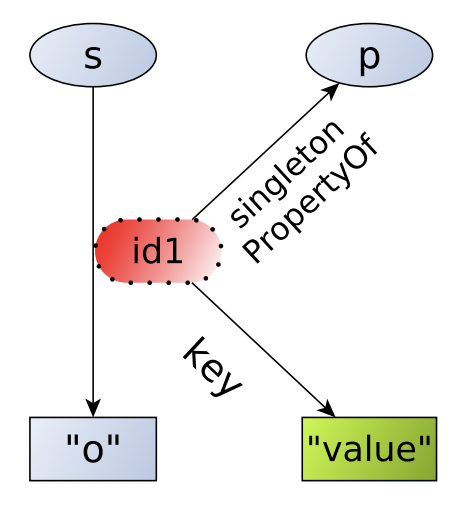 Схема реификации через синглтон-предикат. Иллюстрация из [1].
Схема реификации через синглтон-предикат. Иллюстрация из [1].
Для примера выше такая схема реификации будет выглядеть так:
dbr:Moscow <predicate1> 1174700 .
<predicate1> rdf:singletonPropertyOf dbo:population .
<predicate1> dbo:year 1902 .
dbr:Moscow <predicate2> 12615882 .
<predicate2> rdf:singletonPropertyOf dbo:population .
<predicate2> dbo:year 2019 .
rdf:singletonPropertyOf необходим для логического вывода оригинального высказывания, например, через правила вывода RDFS.
SPARQL-запрос к такой схеме может выглядеть так:
SELECT ?population ?year WHERE {
dbr:Moscow ?singleton ?population .
?singleton rdf:singletonPropertyOf dbo:population .
?singleton dbo:year ?year .}
ORDER BY ASC (?year)
Синглтон-предикаты позволяют работать с именованными графами, но к недостаткам стоит отнести нарушение однородности графа - в общем случае у каждого триплета будет уникальный предикат, что усложнит построение индексов и выполнение SPARQL запросов, логический вывод, и особенно усложнит задачу предсказания связей между сущностями из-за измененного распределения предикатов по субьектам и объектам.
Предикаты-компаньоны (Companion predicates)
Данная схема также вводит уникальные предикаты, но не для каждого триплета в графе, как синглтон-предикаты, а для каждого уникального субъекта. При этом используется соглашение об именах, где каждому использованию предиката p с одним и тем же субъектом назначается растущий ID, и у каждого уникального предиката есть SID, ссылающийся на метаданные и дополнительные триплеты:
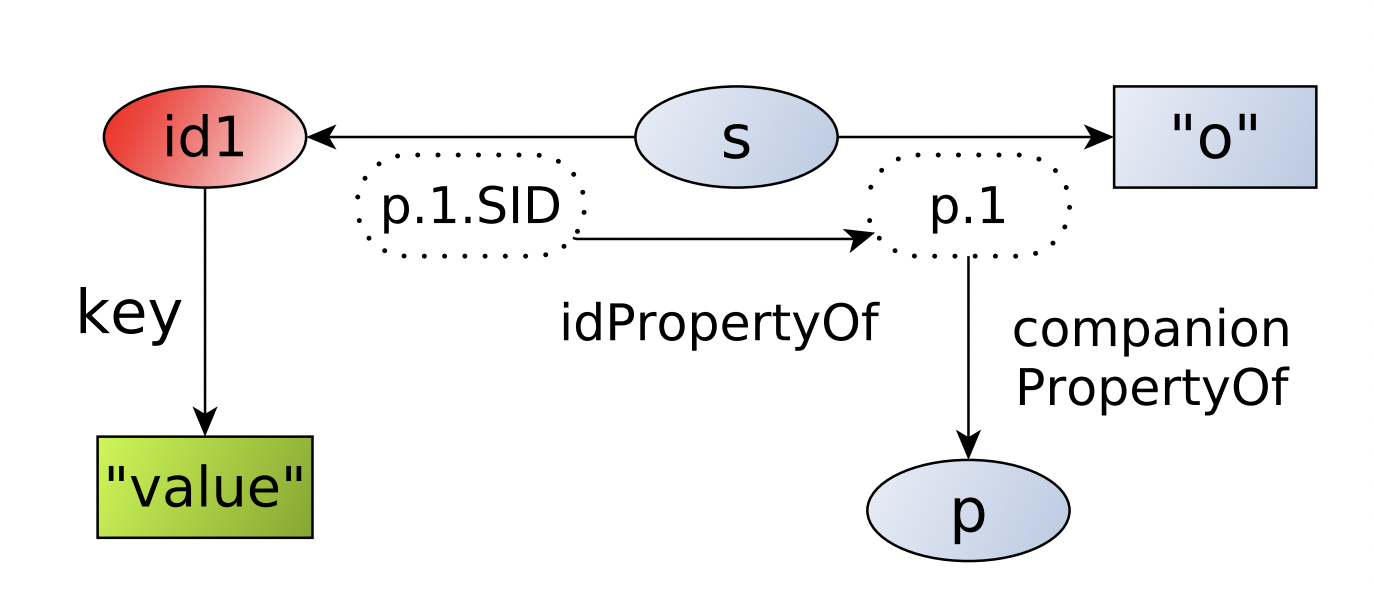 Схема реификации через предикат-компаньон. Иллюстрация из [1].
Схема реификации через предикат-компаньон. Иллюстрация из [1].
Для примера выше такая схема реификации будет выглядеть следующим образом:
dbr:Moscow dbo:population.1 1174700 ;
dbo:population.1.SID <statement1> ;
dbo:population.2 12615882 ;
dbo:population.2.SID <statement2> .
<statement1> dbo:year 1902 .
<statement2> dbo:year 2019 .
dbo:population.1.SID rdf:idPropertyOf dbo:population.1 .
dbo:population.1 rdf:companionPropertyOf dbo:population .
dbo:population.2.SID rdf:idPropertyOf dbo:population.2 .
dbo:population.2 rdf:companionPropertyOf dbo:population .
Для связи компаньонов и SID-предикатов с компаньонами используются специальные свойства rdf:companionPropertyOf и rdf:idPropertyOf, соответственно. SPARQL-запрос для такой схемы:
SELECT ?population ?year WHERE {
{ dbr:Moscow ?companion ?population .
?companion rdf:companionPropertyOf dbo:population
?companionID rdf:idPropertyOf ?companion . }
{ ?companionID dbo:year ?year .}
} ORDER BY ASC (?year)
В отличие от схемы с синглтон-предикатами, схема с компаньонами сгенерирует в нашем примере четыре новых предиката. К недостаткам стоит отнести сложность моделирования, проблемы с однородностью и распределением предикатов в графе, а также большое число вспомогательных триплетов, необходимых для логической связности нового графа.
RDR, RDF*
Некоторые СУБД реализуют собственные схемы реификации. Например, Blazegraph ввел Reification Done Right [4], который дал начало расширениям RDF* и SPARQL* [5].
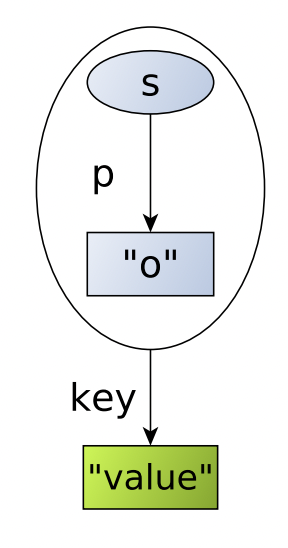 Схема реификации Reification Done Right. Иллюстрация из [1].
Схема реификации Reification Done Right. Иллюстрация из [1].
RDF* - расширение стандарта RDF для более простой работы с реификацией. RDF* вводит как новый RDF Term синтаксическую конструкцию с двумя угловыми скобками, в которые можно поместить описываемое высказывание. Для нашего примера выше это будет выглядеть так:
<< dbr:Moscow dbo:population 1174700 >> dbo:year 1902 .
<< dbr:Moscow dbo:population 12615882 >> dbo:year 2019 .
Предложенная RDF* конструкция является “синтаксическим сахаром”, легко транслируемым в стандартный RDF по произвольной схеме. В настоящее время такие вложенные триплеты транслируются в высказывания по схеме стандартной RDF реификации через rdf:Statement. В дополнение, RDF* имеет формальную модель, в которой вводит понятие RDF* триплета, RDF* графа и SPARQL* запроса к RDF* графу.
SPARQL* запрос к такой схеме также использует новый синтаксис:
SELECT ?population ?year WHERE {
<< dbr:Moscow dbo:population ?population >> dbo:year ?year .
}
RDF* поддерживает триплеты с высказыванием на позиции субъекта или объекта. Реификация одного и того же уникального триплета несколькими дополнительными свойствами транслируется в один и тот же rdf:Statement, что может налагать ограничения на логическую модель.
RDF* и SPARQL* получили распространение в сообществе, поддержка этих практик уже присутствует во многих СУБД, также есть инструменты преобразования графов и запросов в RDF* и обратно. На концептуальном уровне RDF* сближает графовые модели RDF и LPG, вводя простой и мощный механизм задания уникальных атрибутов уникальным триплетам.
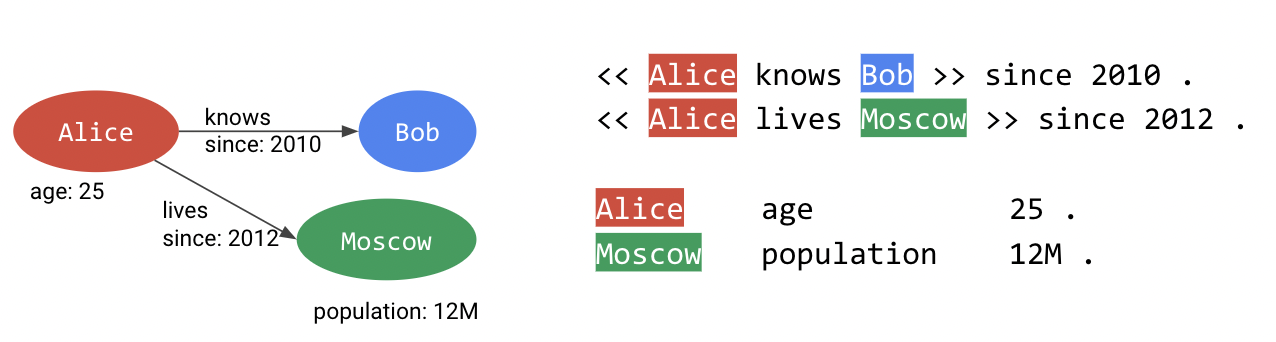
Теперь любой LPG граф может быть представлен как RDF* граф. Более того, у RDF* определен как надможество RDF с сохранением формальной семантики (и вводом дополнительных аксиом).
Wikidata
Wikidata - открытый граф знаний, из которого Wikipedia получает факты для инфобоксов. Модель графа Wikidata не основана на RDF, но может быть экспортирована как в RDF, так и в JSON.
Wikidata использует собственную модель данных и реификации Wikidata Statement Model [6], в которой утверждения (claims) (аналогичные statements в RDF) могут иметь квалификаторы (qualifiers) вида “ключ-значение” (аналогичные метаданным в высказываниях RDF при реификации). Квалификаторы задают контекст, в котором данное утверждение правдиво, например, временные рамки брака или год получения значения населения для города или страны. К каждому высказыванию в Wikidata может быть прикреплен специальный предикат, указывающий на источник происхождения конкретного значения. В RDF модель данных Wikidata может быть представлена так:
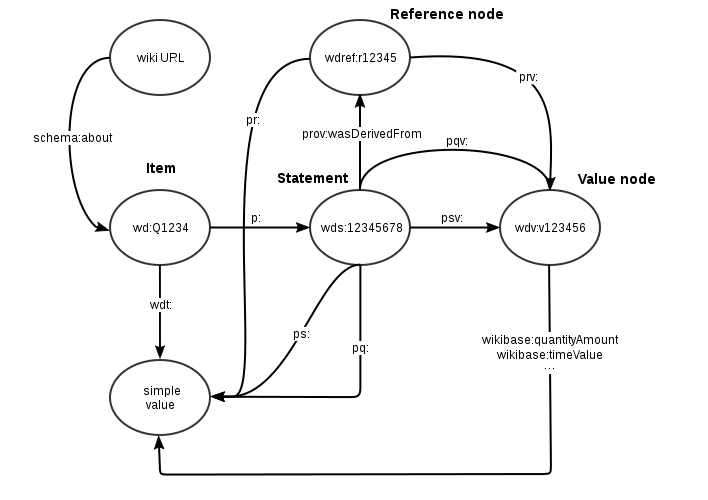 Модель данных Wikidata в RDF [6]
Модель данных Wikidata в RDF [6]
На концептуальном уровне Wikidata - коллекция сущностей (Entity). Сущности подразделяются на четыре вида:
- Предметы (Item) - имеют префикс Q с числовым идентификатором, например
Q649(Moscow), - Предикаты (Property) - имеют префикс P с числовым идентификатором, например
P1082(population) - Лексемы (Lexeme) - имеют префикс L с числовым идентификатором, например,
L10(глагол describe) - Классовые формы (Entity Schema) - имеют префикс E с числовым идентификатором, например
E11(film festival)
Каждая сущность может иметь
- Каноническое название (label) на разных языках
- Описание (description) на разных языках
- Синонимы (aliases) на разных языках
- Высказывания (Statements), состоящие из утверждений (claims) и ссылок на источники.
Рассмотрим модель данных на примере сущности, описывающей Москву в Wikidata.
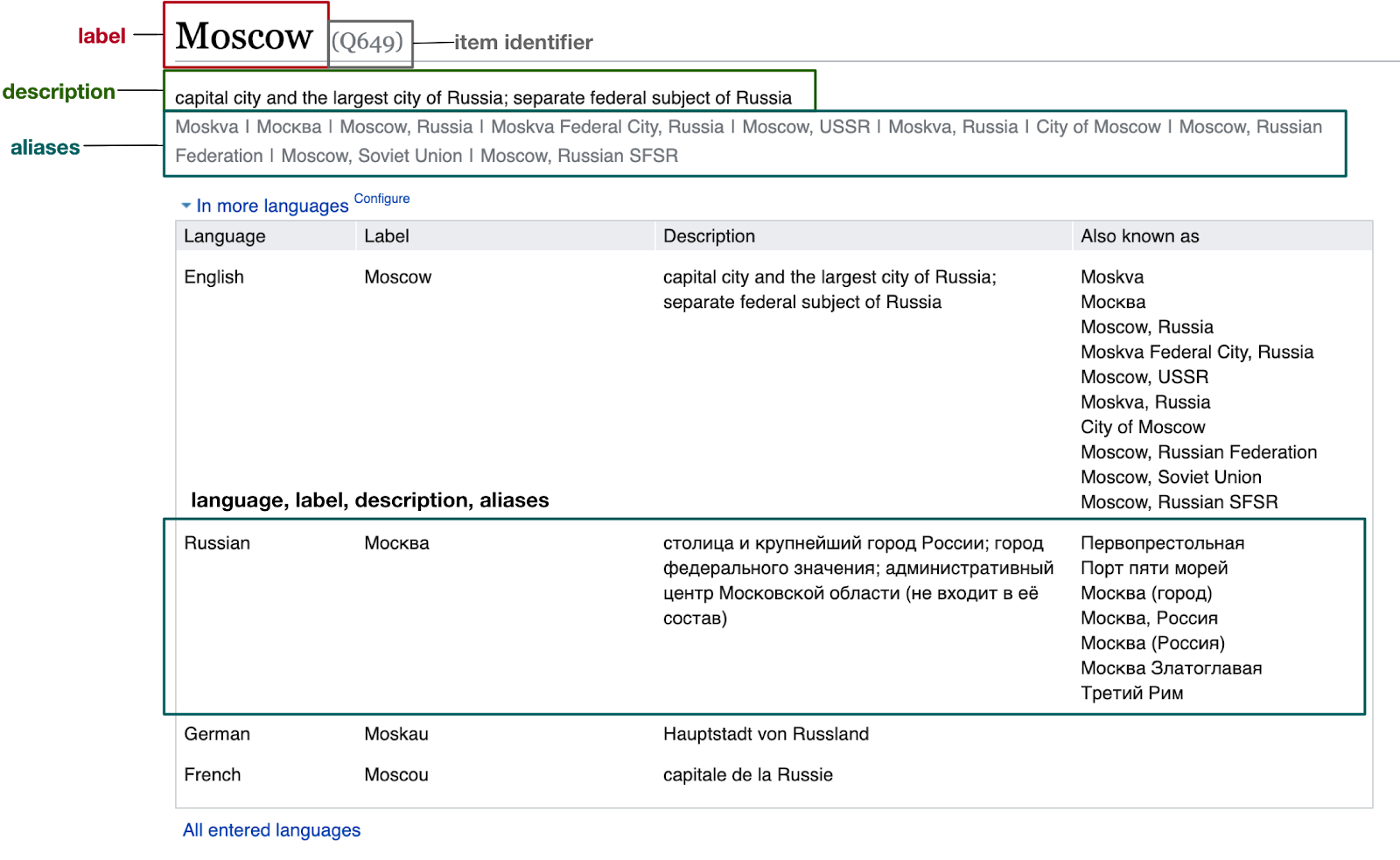 Описание сущности
Описание сущности Q649 в Wikidata
Уникальный идентификатор сущности Q649 описывает сущность с каноническим названием Moscow, отдельно содержится описание и набор синонимов. Название, описание и синонимы могут быть представлены в нескольких языках, в тч на русском.
Сущность Q649 (Item) содержит набор высказываний (Statements), сгруппированных по предикатам. Например, высказывание о населении содержит набор утверждений, содержащих данные о населении Москвы в разные годы:
 Утверждение о населении сущности
Утверждение о населении сущности Q649 в Wikidata
Здесь утверждение содержит предикат population (Wikidata ID: P1082), ссылку на детальное содержимое Value Node (внутреннее представление, не показано на рисунке) и простое числовое значение 12,615,882 (simple value). Value Node также содержит простое числовое значение 12,615,882. Утверждение содержит квалификатор point in time (P585) со значением 2019, указывающем на год получения конкретного значения населения. Утверждение также содержит ссылки на документы (Reference Nodes), откуда это значение населения было получено.
Каждое утверждение имеет некоторый ранг, который курируется редакторами Wikidata. Ранги позволяют описывать текущий статус данного утверждения - предпочитаемое, обычное или устаревшее. Кроме того, в Wikidata существует понятие “истинного высказывания” (truthy statement), которое назначается предпочитаемым утверждениям высоких рангов. Истинные высказывания для предиката имеют особый префикс wdt: (например, wdt:P1082) и содержат значение напрямую (квалификаторы опускаются), тогда как обычные высказывания имеют префикс p: (например, p:P1082) и ведут к другой вершине графа, описывающей утверждение.
Проиллюстрируем эту конфигурацию на примере населения Москвы:
wd:Q649 p:P1082 wds:Q649-1d5ed79d-4534-585a-41c1-395c3f602722 . # содержит утверждение о населении Москвы за 2019 год
wd:Q649 p:P1082 wds:Q649-2803B5B5-23C8-4C6F-94DD-855CF31CDB63 . # содержит утверждение о населении Москвы за 1902 год
wd:Q649 wdt:P1082 12,615,882 . # truthy statement о текущем населении Москвы
В силу особенности модели данных в Wikidata существует большое число префиксов. Более детальные сведения о модели и префиксах можно найти в официальной документации [6].
Часто используемые префиксы Wikidata
| Префикс | Описание |
|---|---|
wd: |
Основной префикс сущностей |
wdt: |
item -> truthy value |
wds: |
statement node |
wdv: |
value node |
wdref: |
reference node |
p: |
predicate -> statement |
pq: |
statement -> qualifier |
ps: |
statement -> simple value |
pqv: |
qualifier -> value node |
psv: |
statement -> value node |
prov: |
statement -> reference |
prv: |
reference -> value node |
pr: |
reference -> simple value |
Wikidata не использует предикаты RDF(S) о классах и их иерархии (rdf:type, rdfs:subClassOf), а вводит вместо них собственные, не обладающие строгой семантикой, поэтому к сущностям в общем случае не применимы понятия RDF/OWL о классах, предикатах и экземплярах (инстансах).
Предметы (Items) в Wikidata могут быть как экземпляром какого-нибудь класса, так и одновременно подклассом другого класса. Например, IBM Watson (Q12253) является экземпляром классов artificial intelligence (Q11660), supercomputer (Q121117), one-of-a-kind computer (Q28542014), и подклассом computer (Q68). В том числе и по этой причине еще не создана непротиворечивая OWL-онтология Wikidata, но существуют таксономии (иерархии) классов и предикатов.
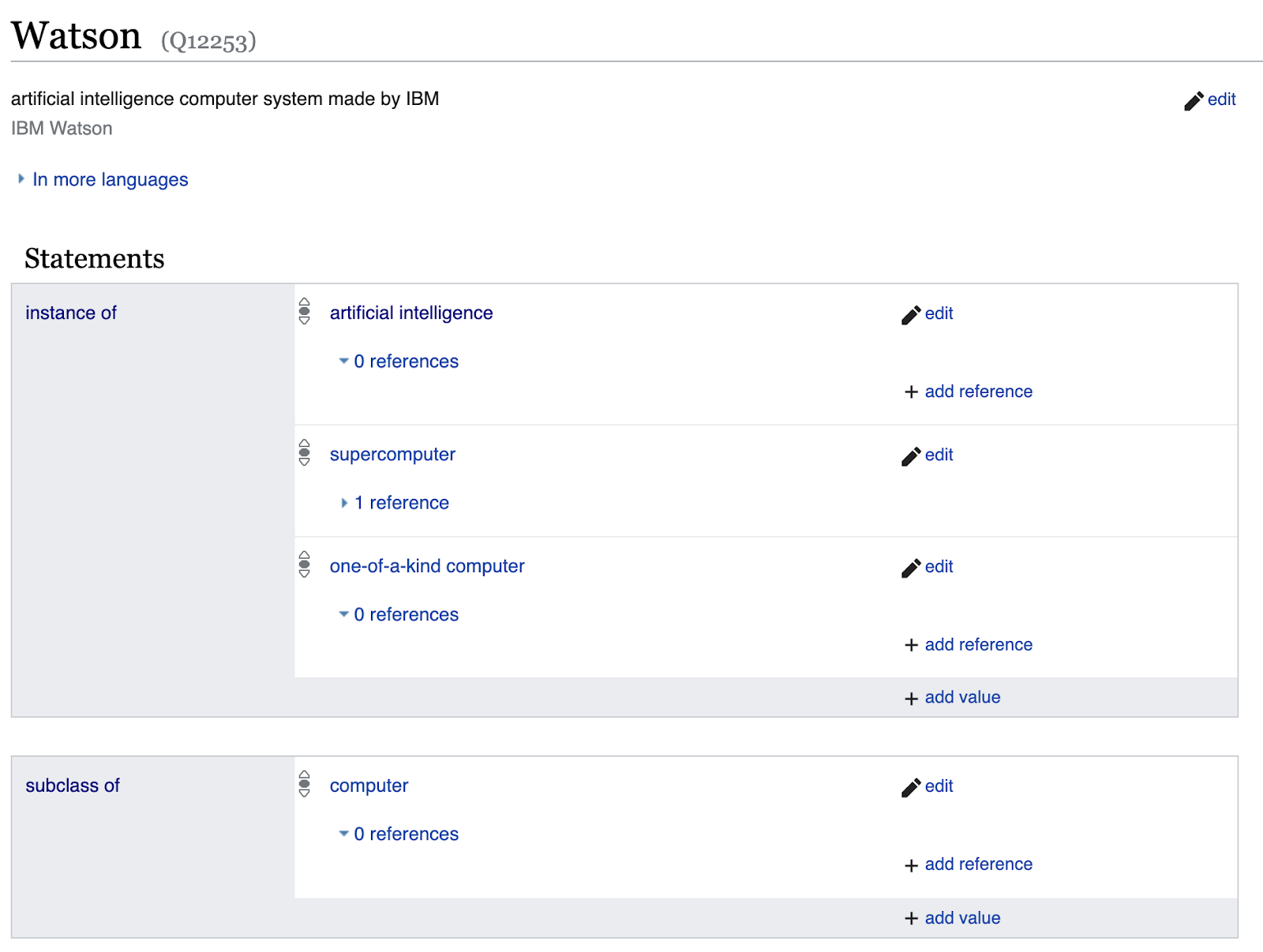 IBM Watson в Wikidata одновременно класс и экземпляр класса
IBM Watson в Wikidata одновременно класс и экземпляр класса
В настоящее время Wikidata является одним из самых больших и популярных графов из имеющихся в открытом доступе. В Wikidata загружают знания как люди, так и компании, все больше научных публикаций в различных областях (обработка естественных языков, базы данных, теория графов) используют Wikidata в своих исследованиях.
Подводя итог механизмам реификации, несколько ислледований [1][2] проанализировали производительность СУБД в работе с графами различных типов реификации.
[1] показывает, что реификация порядка 8500 высказываний может привести к генерации миллионов вспомогательных высказываний и потреблении большого количество памяти, что обуславливает необходимость оптимизаций. С оптимизациями различные механизмы генерируют порядка 100000 высказываний.
Загрузка реифицированных графов в СУБД может занять разное время в зависимости от способа индексации. Согласно [1], собственно способ реификации не так сильно влияет на время загрузки и размер базы, сколько от конкретной СУБД. В Stardog загрузка 650 миллионов триплетов стандартной схемы реификации занимает меньше часа и около 32 Гб места на диске, тогда как Blazegraph требует порядка семи часов и 60 Гб места на диске. Анализ производительности запросов в [1][2][3] не выявляет конкретного предпочтительного варианта, но показывает, что скорость исполнения зависит от логической модели построения графа и сложности запросов.
Валидация (Validation)
В практических применениях графов знаний, как и прочих информационных систем, как правило, необходимо оценивать параметры качества системы. Для графов знаний стандартные параметры еще не определены, но ведутся активные исследования по качеству содержимого графов. Существует несколько предложений, получивших в деловом и исследовательском сообществах значительную поддержку.
Оценка качества графов знаний - задача нетривиальная и задействует несколько различных критериев:
- Синтаксическая корректность оценивает физическое представление графов. Для больших графов СУБД выполняет проверку при загрузке и индексировании
- Семантическая корректность оценивает логическую непротиворечивость. В этой главе мы рассмотрим способы поддержания семантической корректности и валидации, в частности, рекомендации SHACL и ShEx.
- Организация информационных потоков и управление знаниями в целом. В условиях, когда граф разрабатывается и используется коллективно (например, в компаниях), большую роль играют внутренние стандарты качества данных, которые затем используются для составления графов знаний.
На более высоком и абстрактном уровне могут указываться основные рекомендации к созданию и поддержке графов, на более конкретном уровне могут создаваться наборы полезных практик и наблюдений, например как в [7]. Концепция юнит-тестов для графов, сходная с тестированием программного кода, требует некоторых формальных критериев. В настоящее время существует два кандидата в стандарты W3C, вводящие такие критерии.
Семантическая валидация графов знаний основана на понятии контура графа (graph shape). Под контуром графа понимается набор ограничений на экземпляры заданного класса, причем ограничения могут быть на тип значения предиката, на разрешенное количество предикатов, на сочетания предикатов и более сложные. Мы рассмотрим два близких по возможностям подхода к валидации графов знаний - Shape Constraint Language (SHACL) и Shape Expression (ShEx).
SHACL
SHACL (Shapes Constraint Language) - язык описания контурных ограничений [8] - был разработан рабочей группой W3C RDF Data Shapes Working Group, первый драфт вышел в 2015 году, а в 2017 году SHACL стал официальной рекомендацией W3C. Изначально SHACL задумывался для объединения существующих подходов к валидации, включая ShEx, но в силу принципиальных различий сообщества решили развивать SHACL и ShEx отдельно.
SHACL состоит из двух частей - SHACL Core и SHACL-SPARQL. Основная часть, SHACL Core, определяет набор RDF-терминов для описания контуров, вводит базовую семантику валидации и формат вывода результатов. Надмножество SHACL-SPARQL использует семантику стандарта SPARQL 1.1 и вводит механизмы, использующие движки обработки SPARQL-запросов.
SHACL основан на Turtle синтаксисе, рассмотрим пример создания контура HumanShape для класса Human, где в числе ограничений определяется, что инстансы Human должны иметь ровно один предикат name с текстовым значением, ровно один предикат gender с заданными значениями :Male, :Female, или простым текстовым значением, максимум один предикат birthDate со значением типа xsd:date, а также в случае использования предиката knows значением должно быть экземпляр такого же типа Human:
:HumanShape a sh:NodeShape;
sh:targetClass :Human ;
sh:property [ # Blank node 1
sh:path schema:name ;
sh:minCount 1;
sh:maxCount 1;
sh:datatype xsd:string ;
] ;
sh:property [ # Blank node 2
sh:path schema:gender ;
sh:minCount 1;
sh:maxCount 1;
sh:or (
[ sh:in (schema:Male schema:Female) ]
[ sh:datatype xsd:string] )
] ;
sh:property [ # Blank node 3
sh:path schema:birthDate ;
sh:maxCount 1;
sh:datatype xsd:date ;
] ;
sh:property [ # Blank node 4
sh:path schema:knows ;
sh:nodeKind sh:IRI ;
sh:class :Human ;
] .
Описанный выше контур создает ограничения на класс, поэтому имеет тип sh:NodeShape, где sh:targetClass задает целевой класс :Human. Каждое ограничение на предикат представлено как неименованная сущность (blank node) - значение предиката sh:property.
Значение sh:path задает URI предиката, на которое накладывается ограничение, sh:minCount / sh:maxCount определяют минимальное/максимальное количество использований данного предиката с определяемым классом, соответственно. Тип значения предиката может описываться несколькими способами: простое литеральное значение (Datatype Property) указывается через sh:datatype, например, sh:datatype xsd:string (для schema:name) или sh:datatype xsd:date (для schema:birthDate).
Если значение должно быть экземпляром класса, то используется предикат sh:class и нужный класс sh:class :Human (для schema:knows). Более сложная комбинация возможных значений для schema:gender объявляется через sh:or как объединение множеств строковых литералов и двух возможных классов schema:Male и schema:Female.
SHACL-валидатор на вход получает исходный RDF граф, граф контуров (shapes graph), и выводит результаты. Так, если на вход подать исходный RDF граф:
:alice a :Human;
schema:name "Alice" ;
schema:gender schema:Female ;
schema:knows :bob .
Валидация пройдет успешно с результатом
[ a sh:ValidationReport ;
sh:conforms true
]
Значение sh:conforms true указывает на успешность валидации, т.к. cущность :alice имеет подходящие значения предикатов schema:name, schema:gender, schema:knows. Предикат schema:birthDate объявлен в контуре как необязательный, поэтому его отсутствие не вносит нарушений.
Однако, если на вход подать
:emily a :Human ;
schema:name "Emily", "Emilee";
schema:gender schema:Female .
Валидатор обнаружит ошибку и сгенерирует отчет:
:report a sh:ValidationReport ;
sh:conforms false ;
sh:result
[ a sh:ValidationResult ;
sh:resultSeverity sh:Violation ;
sh:sourceConstraintComponent sh:MaxCountConstraintComponent ;
sh:sourceShape ... ; # blank node 1
sh:focusNode :emily ;
sh:resultPath schema:name ;
sh:resultMessage "More than 1 values" ] .
В отчете содержится указание на тип ошибки, место ошибки (сущность и предикат), а также человекочитаемое описание ошибки.
В SHACL существует два типа контуров: контур узла (node shape) и контур предиката (property shape). Контур узла применяется к целевому узлу - в примере выше :HumanShape объявляется как sh:NodeShape, применяющийся к классу :Human. Контур предиката применяется к одному предикату или комбинации нескольких. В примере выше :HumanShape содержит четыре контура предикатов, объявляемых через sh:property. Комбинации предикатов соответствуют property paths SPARQL 1.1. В контур предиката можно включить ограничения на тип значения, количество применений для инстанса, максимальную длину цепи предикатов, совместность и несовместность предикатов в цепи, и многое другое [8], [9].
SHACL-SPARQL является надмножеством SHACL-Core, т.е. системы, использующие SHACL-SPARQL обязаны поддерживать все конструкции SHACL-Core, тогда как обратное не требуется. SHACL-SPARQL обладает большей выразительностью и позволяет создавать более сложные правила валидации. В SHACL-SPARQL контур содержит SPARQL-запрос, который выполняется и анализируется валидатором, и объявляется через предикат sh:sparql. SPARQL-контур ниже формулируется через sh:sparql и сущность типа sh:SPARQLConstraint. Этот объект может содержать человекочитаемое описание проверки и набор префиксов для запроса. Сам запрос хранится как значение предиката sh:select. Например, контур ниже проверяет, эквивалентно ли значение предиката schema:name конкатенации строк schema:givenName и schema:familyName (имя и фамилия):
:UserShape a sh:NodeShape ;
sh:targetClass :Human ;
sh:sparql [
a sh:SPARQLConstraint ;
sh:message "schema:name must equal schema:givenName+schema:familyName";
sh:prefixes [
sh:declare [
sh:prefix "schema" ;
sh:namespace "http://schema.org/"^^xsd:anyURI ;
]
] ;
sh:select
"""SELECT $this (schema:name AS ?path) (?name as ?value)
WHERE {
$this schema:name ?name .
$this schema:givenName ?givenName .
$this schema:familyName ?familyName .
FILTER (!isLiteral(?value) ||
!isLiteral(?givenName) ||
!isLiteral(?familyName) ||
concat(str(?givenName), ' ', str(?familyName))!=?name
)
}""" ;
] .
Стоит заметить, что в запросе появился конструкт $this, который указывает на текущий проверяемый узел (инстанс класса :Human в нашем примере). В FILTER-части запроса объявлены ограничения на значения предикатов - они должны быть строками, а также на конкатенацию двух значений, чтобы она была эквивалентна другому значению.
Подробные спецификации и возможности SHACL указаны в официальной W3C рекомендации [8] и документации [9]. SHACL поддерживается компанией TopQuadrant, реализующей поддержку SHACL в своем ПО, а также предложившей open source реализацию валидации. Реализации доступны на Java, JS, Python.
ShEx
ShEx (Shape Expressions) - язык описания структуры RDF графов. ShEx [10] был разработан в 2013 году, актуальная версия ShEx 2.1 датирована 2018 годом. ShEx был отправлен в W3C как member submission, однако, рекомендацией W3C в конечном счете стал SHACL. ShEx, в отличие от SHACL, представляет собой больше грамматику для создания RDF графов, но оба подхода позволяют объявлять контуры графа и налагать ограничения на узлы и ребра. ShEx существует в трех изоморфных сериализациях:
- ShExC - компактный синтаксис для человекочитаемости
- ShExJ - синтаксис на основе JSON-LD
- ShExR - представленный как RDF-граф на основе JSON-LD документа.
Рассмотрим, как в ShEx задать тот же самый контур, что мы конструировали в SHACL - инстансы класса Human должны иметь ровно один предикат name с текстовым значением, ровно один предикат gender с заданными значениями :Male, :Female, или простым текстовым значением, максимум один предикат birthDate со значением типа xsd:date, а также в случае использования предиката knows значением должен быть экземпляр такого же типа Human:
PREFIX : <http://example.org/>
PREFIX schema: <http://schema.org/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
:Human {
schema:name xsd:string ;
schema:birthDate xsd:date? ;
schema:gender [ schema:Male schema:Female ] OR xsd:string ;
schema:knows IRI @:Human*
}
Объявления префиксов схожи с Turtle, и, в сравнении с SHACL, ShEx предлагает более компактный синтаксис. Ограничения делятся на ограничения на узлы (node constraints) и ограничения на триплеты (triple constraints). Ограничения на узлы задаются без учета предикатов, и только указывают тип значения предиката - литерал или сущность определенных типов, фасеты из XML Schema, или перечисление возможных вариантов. Так, в примере выше xsd:string, xsd:data, [ schema:Male schema:Female ] OR xsd:string, IRI @:Human являются node constraints.
Фасеты, определенные в XML Schema, позволяют задавать сложные ограничения на литералы [10].
Ограничения на узлы могут задаваться списком с перечислением разрешенных значений (например, [ schema:Male schema:Female ]), а также комбинировать с логическими операторами (например, [ schema:Male schema:Female ] OR xsd:string разрешает или одно из двух значений в списке, или литерал строкового типа)
Ограничения на триплеты задают разрешенную комбинацию предиката, значения, и количество повторений данного предиката у сущности, при этом значение по умолчанию (если не задано иное) равно единице. Комбинация ограничений на триплеты и образует контур класса. Так, в примере выше schema:name xsd:string является triple constraint, и предикат schema:name может применяться только один раз. Количества повторений регулируются специальными символами, похожими на регулярные выражения:
*- ноль раз или больше?- ноль или один раз+- один и более раз{i, j}- не менее i, но не более j раз{m}- ровно m раз{m, }- m и более раз
Таким образом, ограничение на триплет schema:knows IRI @:Human* указывает, что значением предиката schema:knows может быть сущность типа :Human, при этом триплет может быть применен сколько угодно раз или не применен вообще. А schema:birthDate xsd:date? указывает, что триплет может быть задан не более одного раза.
При заданном контуре класса :Human, следующие инстансы будут валидированы как принадлежащие этому классу:
:alice schema:name "Alice" ;
schema:gender schema:Female ;
schema:knows :bob .
:bob schema:gender schema:Male ;
schema:name "Robert";
schema:birthDate "1980-03-10"^^xsd:date .
С другой стороны, следующий инстанс не пройдет проверку в силу отсутствия корректного предиката schema:name (задан только foaf:name).
:frank foaf:name "Frank" ;
schema:gender: schema:Male .
ShEx 2.0 ввел новые возможности в области организации запросов к валидируемому графу с помощью спецификации Shape Map (отображение контуров). Fixed Shape Map содержит селекторы узлов графа, которые являются входной точкой процесса валидации, например:
:alice@:User,
:alice@:Employee,
:bob@:User
Query Shape Map содержит набор графовых шаблонов (triple patterns), которые могут содержать конкретные сущности (как в fixed shape map), так и графовые пути, которые необходимо найти в исходном графе. Например:
{ FOCUS schema:worksFor _ }@:User,
{ FOCUS rdf:type schema:Person}@:User,
{ _ schema:worksFor FOCUS }@:Company
Result Shape Map содержит результаты работы валидатора - набор удовлетворяющих и неудовлетворяющих сущностей с человекочитаемым обоснованием.
| node | shape | result | reason |
|---|---|---|---|
| node1 | Shape1 | pass | |
| node2 | Shape1 | fail | reason |
Подробные спецификации и возможности ShEx указаны в официальной документации [10]. Реализации доступны на множестве платформ, включая Java, JS, Python, Ruby, Haskell.
ShEx в Wikidata
ShEx официально поддерживается в Wikidata с мая 2019 года [11], став четвертым глобальным типом. Контуры ShEx имеют префикс E и уникальный числовой идентификатор. Например, следующий контур (wd:E10) проверяет сущность на принадлежность к контуру Human.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
start = @<human>
<human> EXTRA wdt:P31 {
wdt:P31 [wd:Q5];
wdt:P18 . * ; # image (portrait)
wdt:P21 [wd:Q6581097 wd:Q6581072]?; # gender
wdt:P19 . ?; # place of birth
wdt:P20 . ?; # place of death
wdt:P569 . ? ; # date of birth
wdt:P570 . ? ; # date of death
wdt:P735 . * ; # given name
wdt:P734 . * ; # family name
wdt:P106 . * ; # occupation
wdt:P1559 . ? ; #name in native language
wdt:P27 @<country> *; # country of citizenship
wdt:P22 @<human> *; # father
wdt:P25 @<human> *; # mother
wdt:P3373 @<human> *; # sibling
wdt:P26 @<human> *; # spouse
wdt:P40 @<human> *; # children
wdt:P1038 @<human> *; # relatives
wdt:P103 @<language> *; # native language
wdt:P1412 @<language> *; # languages spoken, written or signed
wdt:P6886 @<language> *; # writing language
rdfs:label rdf:langString+;
}
Контур определяет, что корректные сущности класса Human должны иметь значением предиката instance of (P31) класс Human (Q5), предиката gender - определенные в списке значения, ровно один предикат place of birth (P19), одно или более occupation (P106) с любыми значениями, одно или более date of birth (P569) с любыми значениями, одно или несколько given name (P735) и family name (P734), а также одно или несколько значений аннотации rdfs:label, при этом значение должно иметь тэг языка (langString).
Wikidata позволяет создавать контуры вручную или автоматически через SPARQL-запросы и производить валидацию произвольных сущностей по произвольному контуру.
Домашнее задание
Попрактикуйтесь составлять SPARQL-запросы к Wikidata endpoint по адресу https://query.wikidata.org/
Префиксы, которые вам могут понадобиться: wd:, wdt:, p:, pq:. Чтобы искать идентификаторы предикатов и сущностей можно воспользоваться автодополнением. Для этого напишите префикс и нажмите Ctrl+Space.
- Получите все
wdt:-значения сущности Albert Einstein (wd:Q937) - Найдите место рождения (
P19) и дату рождения (P569) Эйнштейна - Найдите, начиная с какого года (
P580) и заканчивая каким (P582) Эйнштейн был гражданином (P27) Швейцарии (wd:Q39)? - Найдите все места работы Эйнштейна (
P108) после 1910 года - Обучаясь (
P69) в каком университете Эйнштейн получил степень (P512) бакалавра (Q787674), специализируясь (P812) на математике (Q853077)? А в каком защитил докторскую (Q849697) по физике (Q413)? - Найдите, сколько раз Эйнштейн был номинирован (
P1411) на Нобелевскую премию по физике (Q38104)? И сколько раз он стал ее лауреатом (P166) ? - На каких физиков (
wdt:P106 wd:Q169470) повлиял (P737) Эйнштейн? - Отобразите на карте все европейские города, где работал (
P937) Эйнштейна ? - Постройте bubble chart населения стран, где жил (
P551) Эйнштейн. - Какие награды получил Эйнштейн, но не получал Ричард Фейнман (
Q39246)?
С помощью визуализатора ShEx викидаты, визуализируйте схемы E63, E176, E42
Использованные материалы и ссылки:
[1] Frey, J., Müller, K., Hellmann, S., Rahm, E., & Vidal, M. E. (2017). Evaluation of Metadata Representations in RDF stores. Semantic Web, (Preprint), 1-25. paper
[2] D. Hernández, A. Hogan, C. Riveros, C. Rojas, and E. Zerega. Querying wikidata: Comparing sparql, relational and graph databases. In The Semantic Web - ISWC 2016 - 15th International Semantic Web Conference, Kobe, Japan, October 17-21, 2016, Proceedings, Part II, pages 88–103, 2016. paper
[3] G. Fu, E. Bolton, N. Queralt-Rosinach, L. I. Furlong, V. Nguyen, A. P. Sheth, O. Bodenreider, and M. Dumontier. Exposing provenance metadata using different RDF models. In Proceedings of the 8th Semantic Web Applications and Tools for Life Sciences International Conference, Cambridge UK, December 7-10, 2015., pages 167–176, 2015. paper
[4] https://wiki.Blazegraph.com/wiki/index.php/Reification_Done_Right
[5] https://w3c.github.io/rdf-star/cg-spec/editors_draft.html
[6] https://www.mediawiki.org/wiki/Wikibase/Indexing/RDF_Dump_Format
[7]] Debattista, Jeremy. Scalable Quality Assessment of Linked Data. Diss. Universitäts-und Landesbibliothek Bonn, 2017. paper
[8] https://www.w3.org/TR/shacl/
[9] https://book.validatingrdf.com/
[10] http://shex.io/
[11] https://www.wikidata.org/wiki/Wikidata:WikiProject_ShEx