Лекция 3
SPARQL и Графовые хранилища
| Материалы | Ссылка |
|---|---|
| Видео | YouTube |
| Слайды | |
| Конспект | здесь |
| Домашнее задание | link |
Видео
В предыдущих лекциях мы рассмотрели основы представления знаний с помощью графовой модели RDF. В этой лекции мы познакомимся ближе со способами физического хранения графов знаний и обработки запросов к ним. Одна из ключевых особенностей графов знаний - аналитика и запросы на уровне, недоступном традиционным реляционным СУБД. Поэтому мы уделим особое внимание графовым (NoSQL) СУБД и языкам запросов.
RDF vs LPG
В настоящее время сложилось два подхода к хранению графов знаний. Первый подход предполагает представление графа в виде семантического RDF-графа, характеристики которых мы рассматривали в предыдущих лекциях. В этом подходе в хранении и обработке опираются больше на ребра графа, и как язык запросов используется SPARQL.
Второй подход - Labeled Property Graph (LPG) - ориентирован более на классические графы в различных вариациях (направленные, взвешенные, гипеграфы, и тд), где используется множество языков запросов, например, Cypher. LPG несколько отличается от RDF, но в основным тем, что как вершины, так и ребра могут иметь атрибуты “ключ-значение”:
:Alice :knows{since: 2010} :Bob .
В RDF и OWL, напомним, атрибуты предикатов ограничены, например, owl:TransitiveProperty, и создавать экземпляры ребер с конкретными атрибутами нельзя. С другой стороны, LPG-графы не имеют семантической модели и не способны к логическому выводу.
Часть 1 - SPARQL
В первой части этой лекции мы рассмотрим стандарт SPARQL для создания и выполнения запросов к RDF-графам. Этот акроним означает SPARQL Protocol and RDF Query Language - рекурсивный акроним, наподобие GNU — GNU’s Not Unix. SPARQL способен эффективно использовать графовую модель представления знаний и имеет базовые механизмы логического вывода. Если язык SQL подразумевает табличную организацию баз данных, то SPARQL изначально создавался именно для графовых данных. SPARQL стандартизирован не только как язык запросов, но как и сетевой протокол взаимодействия RDF СУБД и формат ответа хранилища на запрос (ResultSet). Первая редакция SPARQL была принята в 2008 году, актуальная версия SPARQL 1.1 принята как стандарт W3C в 2013 году.
Basic Graph Pattern
Основной строительный блок SPARQL-запроса — образ или шаблон подграфа (graph pattern), который задает топологию перемещения по узлам и ребрам графа. Синтаксис SPARQL основан на Turtle, что мы рассмотрели в предыдущей лекции. Переменные указываются через ? или $, например ?name или $title. Шаблоном подграфа называется RDF триплет, содержащий одну или несколько переменных на месте субъекта, предиката и/или объекта. Например, в шаблоне
?s ?p ?o
на всех трех местах стоят переменные, и запрос вернет все имеющиеся пути (триплеты) в графе. В шаблоне
:Alice ?p :Bob
предикат является переменной, и запрос вернет все ребра (предикаты), соединяющие напрямую сущности :Alice и :Bob. Множество шаблонов (graph patterns) образует базовый шаблон графа (Basic Graph Pattern, BGP), который в общем случае представляет собой конъюнктивный шаблон, т.е. последовательность простых шаблонов, объединенных логическим И. Например,
{ :Alice :knows ?x .
?x :livesIn ?city . }
Идея работы SPARQL в поиске в заданном RDF графе подграфа, соответствующего базовому шаблону графа (BGP). Пусть у нас есть исходный граф, состоящий из следующих триплетов:
:ITMO_University rdf:type :University .
:ITMO_University rdf:type :Research_Institution .
:ITMO_University :locatedIn :Saint_Petersburg .
:University rdfs:subClassOf :Educational_Institution .
Рассмотрим следующий запрос получения всех семантических типов Университета ИТМО в некотором графе:
SELECT ?type WHERE {
ITMO_University rdf:type ?type .
}
Образ подграфа содержит один триплет с одной неизвестной переменной ?type. Система исполнения запросов совмещает образ графа в запросе с подграфом, связанным с ITMO University, и фильтрует предикаты по названию (rdf:type). В результате остаются только исходящие ребра предиката rdf:type, а конечные узлы этих ребер и являются ответом на данный запрос - в нашем случае это будут сущности :University и :Research_Institution. Ответ на запрос по стандартному формату будет таблицей:
| ?type |
|---|
| :University |
| :Research_Institution |
Общая структура SPARQL запроса выглядит следующим образом:
PREFIX ex: <URI> . # определения префиксов, используемых в запросе
# тип запроса # искомые переменные # граф для поиска
SELECT ?x ?y FROM
WHERE { # BGP
}
# модификаторы результатов
ORDER BY <> LIMIT <> OFFSET <>
Префиксы, как правило, используют для улучшения читаемости запроса. Во время обработки запроса префикс заменяется полным URI. SPARQL определяет несколько типов запросов.
SELECT
SELECT возвращает таблицу результатов с конкретными значениями переменных (projections), найденными в графе. Например, при заданном графе:
:Alice :knows :Bob .
:Alice :knows :Ann .
следующий запрос вернет все субъекты, имеющие исходящий предикат :knows:
SELECT ?s WHERE {
?s :knows ?o .
}
Результатом будет таблица
| ?s |
|---|
| :Alice |
| :Alice |
Заметим, что сущность :Alice дважды представлена в ответе, так как существует два триплета, удовлетворяющие шаблону. Чтобы избавиться от дубликатов часто используют ключевое слово DISTINCT:
SELECT DISTINCT ?s WHERE {
?s :knows ?o .
}
Вывод будет дедуплицированным: | ?s | | —- | | :Alice |
ASK
ASK возвращает булево значение True/False, говорящее, можно ли искомый BGP наложить на исходных граф. Например,
:Alice :knows :Bob .
:Alice :knows :Ann .
Следующий запрос вернет True
ASK {
:Alice :knows :Bob .
} # True
А следующий - False
ASK {
:Alice :knows :John .
} # False
CONSTRUCT
CONSRUCT возвращает триплеты со значениями переменных из BGP. Пусть существует граф
:Alice :livesInCity :Saint_Petersburg .
:Saint_Petersburg :country :Russia .
И дан запрос:
CONSTRUCT {
?x :livesInCountry ?country .
} WHERE {
?x :livesInCity ?city .
?city :country ?country .
}
Данный запрос вернет новый триплет
:Alice :livesInCountry :Russia
другими словами, создаст новое ребро в графе между узлами :Alice и :Russia.
DESCRIBE
DESCRIBE возвращает описание ресурса. Можно задавать URI ресурса напрямую или получать его из результатов сравнения BGP.
DESCRIBE :Alice
DESCRIBE ?x WHERE
{?x :knows: Bob .}
Какие именно триплеты-описание искомой сущности вернет запрос, зависит от реализации в каждом конкретном хранилище. Как правило, это все исходящие пары “предикат-значение”.
SPARQL 1.1 определяет пару дополнительных типов запросов INSERT / DELETE для загрузки и удаления триплетов из графа, соответственно.
Ключевое слово FROM указывает конкретный граф в хранилище для исполнения запроса. Как правило, хранилища позволяют загружать графы с собственным уникальным идентификатором (named graph). Если FROM опустить, то запрос будет обработан по всем имеющимся именованным графам в хранилище.
BGP запроса может содержать конъюнкцию графовых шаблонов любой длины. Необходимое условие, однако, чтобы шаблоны объединялись минимум одной общей переменной, по которой будет проводиться операция соединения (JOIN). По статистике [0], большая часть запросов к реальным хранилищам - SELECT, поэтому следующие примеры будет рассматривать как SELECT-запросы.
Модификаторы результатов изменяют вывод запроса:
ORDER BY (ASC/DESC)- сортирует вывод в порядке возрастания или убывания значения переменной или переменных. Если переменная содержит текст или URI, то сортировка лексикографическая (но URI считается меньшим по значению, чем литерал).SELECT ?x WHERE { :Alice :knows ?x . } ORDER BY ASC(?x)LIMITограничивает число возвращаемых результатов, например следующий запрос в общем случае вернет все имеющиеся триплеты графа, а в случае сLIMITтолько ограниченное количество.SELECT * WHERE { ?s ?p ?o . } LIMIT 10OFFSETчасто используется вместе сLIMITдля вывода большого количества результатов по страницам (pagination).OFFSETсдвигает внутренний счетчик вывода результатов на определенное число, например, выводить по 10 триплетов, начиная с 20го. Поскольку сдвиг обычно используется для множественных запросов, перебирающих страницы, следует зафиксировать общий для всех запросов порядок триплетов при помощи ORDER BY.SELECT * WHERE { ?s ?p ?o . } ORDER BY ASC(?s) ASC(?p) DESC(?o) OFFSET 20 LIMIT 10
Итак, теперь нам известен базовый набор ключевых слов для построения SPARQL запросов. Например, следующий запрос возвратит авторов и названия их заметных произведений, отсортированных по возрастанию по авторам, причем количество результатов ограничено 100 со смещением вывода на 10:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dbo: <http://dbpedia.org/ontology/>
SELECT DISTINCT ?author ?title
FROM <http://dbpedia.org>
WHERE {
?author rdf:type dbo:Writer ;
rdfs:label ?author_name ;
dbo:notableWork ?work .
?work rdfs:label ?title .
} ORDER BY ASC(?author_name) LIMIT 100 OFFSET 10
Заметим, что неименованные сущности (blank nodes) могут находиться в шаблоне подграфа только на позиции субъекта или объекта, при этом их нельзя материализовать как результат SELECT-запроса.
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbp: <http://dbpedia.org/property/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?name ?date
FROM <http://dbpedia.org>
WHERE {
_:x rdf:type dbo:Writer ;
dbp:award [ dbp:awardName ?name ;
dbp:awardDate ?date ]}
FILTER
В больших графах простые запросы возвращают очень много результатов, что в целом делает исполнение запросов более медленным, а обработку более сложной. Часто нам нужен не просто шаблон подграфа со значениями, а шаблон с определенными значениями. Такие шаблоны образуются ключевым словом FILTER:
{ pattern FILTER {function | operator} }
Например, следующий запрос вернет писателей и их значительные произведения длиной более 500 страниц с названиями на английском языке:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dbo: <http://dbpedia.org/ontology/>
SELECT DISTINCT ?author ?title
FROM <http://dbpedia.org>
WHERE {
?author rdf:type dbo:Writer ;
rdfs:label ?author_name ;
dbo:notableWork ?work .
?work rdfs:label ?title FILTER (lang(?title)=”en”);
dbo:numberOfPages ?numPages FILTER (?numPages > 500) .
} ORDER BY ASC(?author) LIMIT 100 OFFSET 10
В этом запросе применены два фильтра: фильтр по языку названия произведения и фильтр по числу страниц. В целом, фильтры:
- Работают для определенного шаблона подграфа
- Тестируют значения с помощью операторов и функций, причем как URI так и литералы.
- Различные типы литералов можно фильтровать строковыми сравнениями, числовыми сравнениями, регулярными выражениями
- Результаты сравнения приводятся к трехзначной логике True/False/Error, таблица истинности которой определена в стандарте [1]
К числу возможностей, доступных при фильтрации, относят:
- Логические:
!(отрицание),&&(И),||(ИЛИ) для логических типов - Математические:
+,-,*,/, для числовых типов - Сравнительные:
>,<,>=,<=,=,!= - Унарные функции-проверки:
isURI(),isLiteral(),isBlank(),bound() - Функции
str(),lang(),datatype(),sameTerm(),langMatches() - Регулярные выражения
regex(string, pattern [, flag]) - Встроенные функции, специфичные для конкретного хранилища, например,
bif:contains()для проверки подстроки в СУБД Virtuoso - Функции для работы с отрицаниями для возможности отфильтровать сущности, которые не содержат определенного шаблона:
NOT EXISTS {pattern},MINUS {pattern}. Доступны с версии SPARQL 1.1
Фильтры можно объединять с помощью логических операторов. Например, для следующего графа:
:John :age 32 .
:John foaf:name "John"@en .
:Tim :age 20.
:Tim foaf:name "Tim"^^xsd:string .
Запрос вернет :Tim и :John:
SELECT DISTINCT ?friend WHERE {
?friend foaf:name ?name;
foaf:age ?age
FILTER (regex(?name, “im”) || ?age > 25)
}
OPTIONAL
Одна из особенностей RDF-графов - неполнота данных, т.е. у двух экземпляров одного класса может быть разных набор предикатов (исходящих ребер). Например, у :John есть атрибут foaf:mbox, а у :Tim нет, при этом оба они принадлежат классу foaf:Person:
:John :age 32 .
:John foaf:mbox “john@example.com” .
:John rdf:type foaf:Person .
:Tim rdf:type foaf:Person .
:Tim :age 20.
BGP при обработке запроса сравниваются полностью, т.е. запрос
SELECT ?s WHERE {
?s rdf:type foaf:Person.
?s foaf:mbox ?mbox. }
Вернет только :John. Ключевое слово OPTIONAL позволяет сделать некоторый шаблон опциональным. По своей работе OPTIONAL похож на LEFT OUTER JOIN в SQL. Синтаксис следует правилу
pattern OPTIONAL {opt_pattern}
Таким образом, запрос
SELECT ?s WHERE {
?s rdf:type foaf:Person.
OPTIONAL {?s foaf:mbox ?mbox.} }
Вернет и :Tim, и :John, так как наличие предиката foaf:mbox становится необязательным.
С другой стороны, чтобы получить только сущность :Tim можно применить негативный фильтр:
SELECT ?s WHERE {
?s rdf:type foaf:Person.
FITLER NOT EXISTS {?s foaf:mbox ?mbox.} }
UNION
Ключевое слово UNION обеспечивает поддержку логического ИЛИ в запросах. С помощью UNION можно объединять несколько BGP с, возможно, немного различающимися конъюнктивными шаблонами. Синтаксис
{BGP} UNION {BGP}
Следующий запрос вернет как людей, на которых повлиял Стивен Кинг, так и тех, кто оказал влияние на самого Стивена Кинга.
SELECT ?influencer ?influenced WHERE {
{dbr:Stephen_King dbo:influenced ?influenced}
UNION
{dbr:Stephen_King dbo:influencedBy ?influencer}
}
SPARQL 1.1
Стандарт SPARQL 1.1 расширил возможности языка в области агрегации результатов и исследования топологии графа.
Для агрегации результатов введено множество новых функций: min(), max(), avg(), sum(), count(), sample(), group_concat(). Например, один из самых используемых запросов возвращает общее количество триплетов в хранилище:
SELECT COUNT(*) as ?num WHERE {
?s ?p ?o .
}
В этом запросе считается количество триплетов, и это значение назначается возвращаемой переменной ?num. В следующем запросе возвращается среднее значение предиката ?age для сущностей типа foaf:Person.
SELECT AVG(?age) as ?av_age WHERE {
?person rdf:type foaf:Person .
?person :age ?age .
}
Для группировки результатов используется новое ключевое слово GROUP BY. Например, следующий запрос вернет писателей, отсортированных по убыванию числа значительных произведений:
SELECT ?author COUNT(?work) as ?num WHERE {
?author rdf:type dbo:Writer ;
dbo:notableWork ?work
} GROUP BY ?author ORDER BY DESC(?num)
Ключевое слово HAVING позволяет задать ограничение на шаблон подграфа с функциями агрегации, например, следующий запрос вернет всех писателей, у которых ровно три значительных произведения:
SELECT ?author COUNT(?work) as ?num WHERE {
?author rdf:type dbo:Writer ;
dbo:notableWork ?work
} GROUP BY ?author
HAVING COUNT(?work) = 3
ORDER BY DESC(?num)
Property paths
Еще одно значительное нововведение SPARQL 1.1 - понятие property paths - возможная последовательность или комбинация предикатов между двумя вершинами. Стоит заметить, что SPARQL накладывает некоторые ограничения на эти последовательности, например, в property paths можно использовать только конкретные предикаты, переменные не разрешаются. В LPG-хранилищах языки запросов позволяют использовать переменные в таких случаях. Предикаты комбинируются следующим образом:
- Альтернативный путь (ребро) через
|- значениях всех ребер, объединенных ИЛИ, будут присвоены искомой переменнойSELECT ?name WHERE { ?person rdfs:label|foaf:name ?name . } - Последовательность предикатов через
/:SELECT ?country WHERE { ?person :visitedCity/:country ?country . } - Путь, проходящий, через цепочку из одного и более
+(или нуль и более —*) предикатов указанного типа:SELECT ?name WHERE { ?s :knows*/:name ?name . } - Инверсные пути через
^- когда субьект-объект предиката заменяются{ ?person foaf:knows/^foaf:knows ?friend } - Негативные пути - то есть заданный property path не должен существовать -
!{ ?person !(:visitedCity+/:country) ?country . }
Больше информации об агрегированных запросах и property paths можно найти в стандарте [2].
SERVICE: Федеративное исполнение
И еще одно нововведение, которое мы будем активно использовать в следующих частях, позволяет в рамках одного запроса опрашивать другие хранилища, поддерживающие SPARQL с помощью ключевого слова SERVICE. Таким образом организуются федеративные запросы, когда необходимо опросить несколько хранилищ, объединить и агрегировать результаты.
Федеративные запросы играют большую роль в интеграции данных в RDF-графы, поэтому механизм их исполнения, обработки и оптимизации мы рассмотрим в следующих лекциях. Пример федеративного запроса, опрашивающего открытые графы DBpedia и Linked Movie Database:
SELECT ?film ?label ?subject WHERE {
SERVICE <http://data.linkedmdb.org/sparql> {
?movie rdf:type movie:film .
?movie rdfs:label ?label .
?movie owl:sameAs ?dbpediaLink
FILTER (regex(str(?dbpediaLink), “dbpedia”))
}
SERVICE <http://dbpedia.org/sparql> {
?dbpediaLink dct:subject ?subject .
}
}
Advanced SPARQL
Рассмотрим несколько более глубоких тем в рамках SPARQL. Стандарт предусматривает в процессе обработки запроса компилировать его в алгебраическое выражение с помощью специальной алгебры, похожей на реляционную алгебру и SQL. Отличия, однако, в графовой модели SPARQL. Знание, как запрос преобразовывается в алгебраическое выражение, позволит создавать оптимальные запросы. Часто запросы, возвращающие одинаковые результаты, выполняются за различное время, и причины этого кроются в преобразовании запроса. Например, запрос
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbr: <http://dbpedia.org/resource/>
SELECT ?s WHERE {
?s ?p ?o FILTER (?p=dbo:director && ?o=dbr:Stephen_Spielberg) }
Будет выполняться во много раз медленнее второго запроса, хотя они возвращают один и тот же результат:
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbr: <http://dbpedia.org/resource/>
SELECT ?s WHERE {
?s dbo:director dbr:Stephen_Spielberg }
Первый запрос компилируется в выражение:
(base <http://example/base/>
(prefix ((dbo: <http://dbpedia.org/ontology/> ))
(prefix (( dbr:<http://dbpedia.org/resource/> ))
(filter (&& (= ?p dbo:director) (= ?o dbr:Stephen_Spielberg))
(bgp (triple ?s ?p ?o))))))
Тогда как второй запрос компилируется в:
(base <http://example/base/>
(prefix ((dbo: <http://dbpedia.org/ontology/> ))
(prefix (( dbr:<http://dbpedia.org/resource/> ))
(bgp (triple ?s dbo:director dbr:Stephen_Spielberg)))
Из первого выражения становится очевидно, что Basic Graph Pattern сперва запрашивает вообще все триплеты в графе, и только затем все они фильтруются по предикату и значению, что в случае больших графов (DBpedia, Wikidata) может привести к отказу в обработке запроса. Напротив, второй запрос сразу содержит конкретный Basic Graph Pattern и не содержит фильтров, что способствует высокой скорости выполнения. В целях оптимизации запросов, как правило, стараются создавать как можно более селективные BGP, которые возвращают как можно меньше временных результатов, и помещать фильтры как можно более глубже в план выполнения, чтобы фильтровать меньше временных результатов.
Reasoning
SPARQL сам по себе не обладает возможностью логического вывода в отличие от RDFS или OWL ризонеров. Иными словами, перед запросом граф должен быть полностью материализован - то есть все новые выведенные триплеты должны быть явно записаны.
Однако, разработчики графовых СУБД часто встраивают в свои решения машины логического вывода разной сложности. Простейший пример - ризонинг по иерархии классов через предикат rdfs:subClassOf. Если задан следующий граф:
:ITMO_University rdf:type :University .
:ITMO_University rdf:type :Research_Institution .
:ITMO_University :locatedIn :Saint_Petersburg .
:University rdfs:subClassOf :Educational_Institution .
То следующий запрос с применением логического вывода по иерархии вернет не только прямые классы (University, Research_Institution) сущности ITMO_University, но и те классы, что являются родителями предыдущих (Educational_Institution):
SELECT ?type WHERE {
:ITMO_University rdf:type ?type .}
Более сложные примеры включают логический вывод по предикату owl:sameAs, профилям OWL 2 или SWRL правилам. Как правило, в каждой СУБД свой способ включить ризонинг во время обработки запросов и свой набор поддерживаемых логических возможностей.
Часть 2 - Хранилища графов знаний
На физическом уровне графы знаний можно хранить несколькими способами.
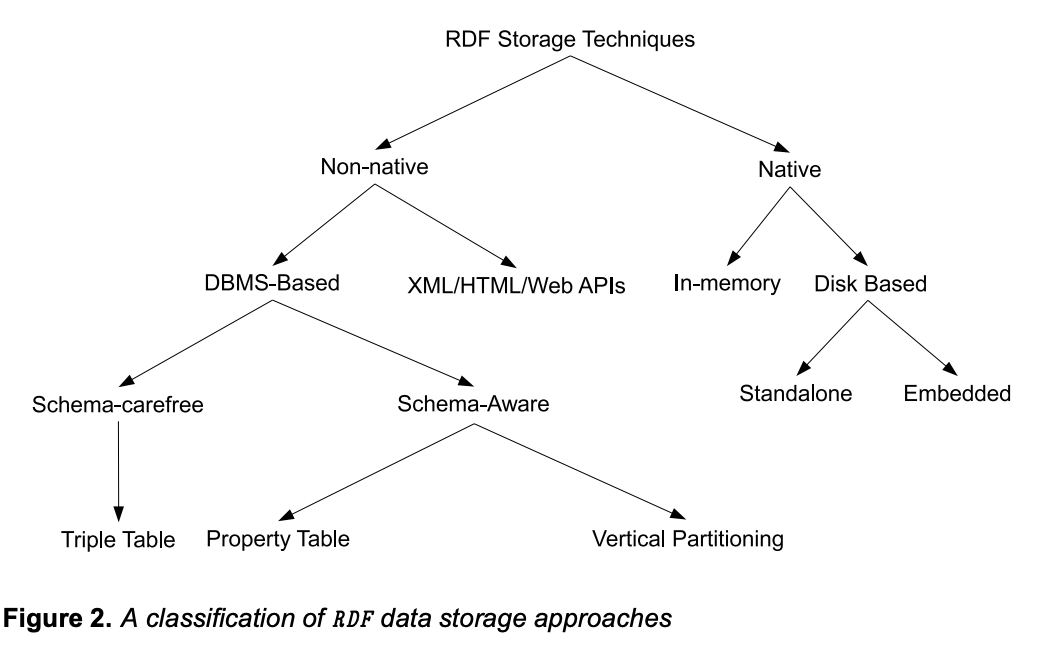 Типы RDF хранилищ [3]
Типы RDF хранилищ [3]
Реляционные
Наиболее простой, но не самый эффективный - хранить компоненты триплета (субъект, предикат, объект) в отдельных колонках реляционной СУБД. С одной стороны, можно использовать достижения теории реляционных баз данных, а с другой стороны для обработки SPARQL-запроса необходимо транслировать его в SQL (или нативный язык СУБД), выполнить в нативном формате, и результат преобразовать в формат вывода SPARQL. Для хранения графа
:ITMO_University rdf:type :University .
:ITMO_University rdf:type :Research_Institution .
:ITMO_University :locatedIn :Saint_Petersburg .
:University rdfs:subClassOf :Educational_Institution .
Таблица может выглядеть следующим образом:
| subject | predicate | object |
|---|---|---|
| :ITMO_University | rdf:type | :University |
| :ITMO_University | rdf:type | :Research_Institution |
| :ITMO_University | :locatedIn | :Saint_Petersburg |
| :University | rdfs:subClassOf | :Educational_Institution |
Производительность и скорость обработки запросов такого хранилища сильно зависит от индексов базы данных. Например, производительность можно повысить, используя только индексы сущностей.
| Entity | ID |
|---|---|
| :ITMO_University | 1 |
| rdf:type | 2 |
| :University | 3 |
| :Research_Institution | 4 |
| :locatedIn | 5 |
| :Saint_Petersburg | 6 |
| rdfs:subClassOf | 7 |
| :Educational_Institution | 8 |
И тогда исходная таблица будет выглядеть так:
| subject | predicate | object |
|---|---|---|
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 1 | 5 | 6 |
| 3 | 7 | 8 |
Недостатком такой схемы, однако, является большое количество промежуточных операций соединения (JOIN). Еще одной формой представления графов в таблице является property table:
| ID | type | :locatedIn | rdfs:subClassOf |
|---|---|---|---|
| ID1 | ID3 | ID6 | NULL |
| ID1 | ID4 | ID6 | NULL |
| ID | type | :locatedIn | rdfs:subClassOf |
|---|---|---|---|
| ID3 | NULL | NULL | ID8 |
| ID4 | NULL | NULL | NULL |
К преимуществам этой схемы относят меньше количество необходимых операций соединения, и представление графа может напоминать реляционную схему если граф сильно структурирован. К недостаткам относят большое число пустых ячеек в случае разреженного графа (коими они обычно являются) и сложность представления сущностей с несколькими значениями одного предиката. Граф хранится в реляционной СУБД, а это значит, что SPARQL-запросы должны транслироваться в SQL-запросы, что часто влечет ухудшение производительности и ограничение на выразительность SPARQL-запросов.
К числу графовых хранилищ, основанных на реляционной модели, можно отнести Apache Jena SDB, Oracle Spatial and Graph.
Нативные RDF хранилища
Нативные хранилища работают напрямую с графовыми объектами, а не с реляционными таблицами. Нативные хранилища часто подразделяются на in-memory и disk-based. В in-memory хранилищах данные целиком расположены в оперативной памяти, что положительно сказывается на скорости работы, но отрицательно на надежности. Disk-based (дисковые) СУБД хранят данные на жестких дисках, что намного надежнее, но медленнее in-memory подходов. Дисковые СУБД могут быть самостоятельными (standalone) или встроенными (embedded). Самостоятельные СУБД не зависят от конкретного приложения и могут быть использованы сторонними сервисами, тогда как встроенные СУБД программно привязаны к конкретному приложению и не могут быть использованы для других сервисов.
Графовые СУБД используют собственные модели хранения данных. К семейству графовых СУБД принадлежат и нативные RDF хранилища. Механизмы физического хранения триплетов разнятся - так, некоторые RDF СУБД хранят и индексируют триплеты в B+-деревьях (RDF3X, Blazegraph), а другие в LSM-деревьях (Stardog). Как правило, нативные RDF СУБД оптимизированы для выполнения SPARQL запросов и логического вывода, чего сложно достичь в реляционных RDF-хранилищах. Гибридные RDF хранилища совмещают компоненты реляционных и нативных систем, например, могут отвечать на SQL запросы, но имеют ограниченные возможности логического вывода. К таким СУБД относят OpenLink Virtuoso и RDF4J.
B+ Trees: RDF-3X
RDF-3X [4] - RDF-хранилище, которое до сих пор является хорошим примером для изучения индексирования и хранения графов, а также сильным бейзлайном для сравнения с другими графовыми СУБД. При загрузке графа, RDF-3X строит сразу несколько индексов.
Three-value indexes
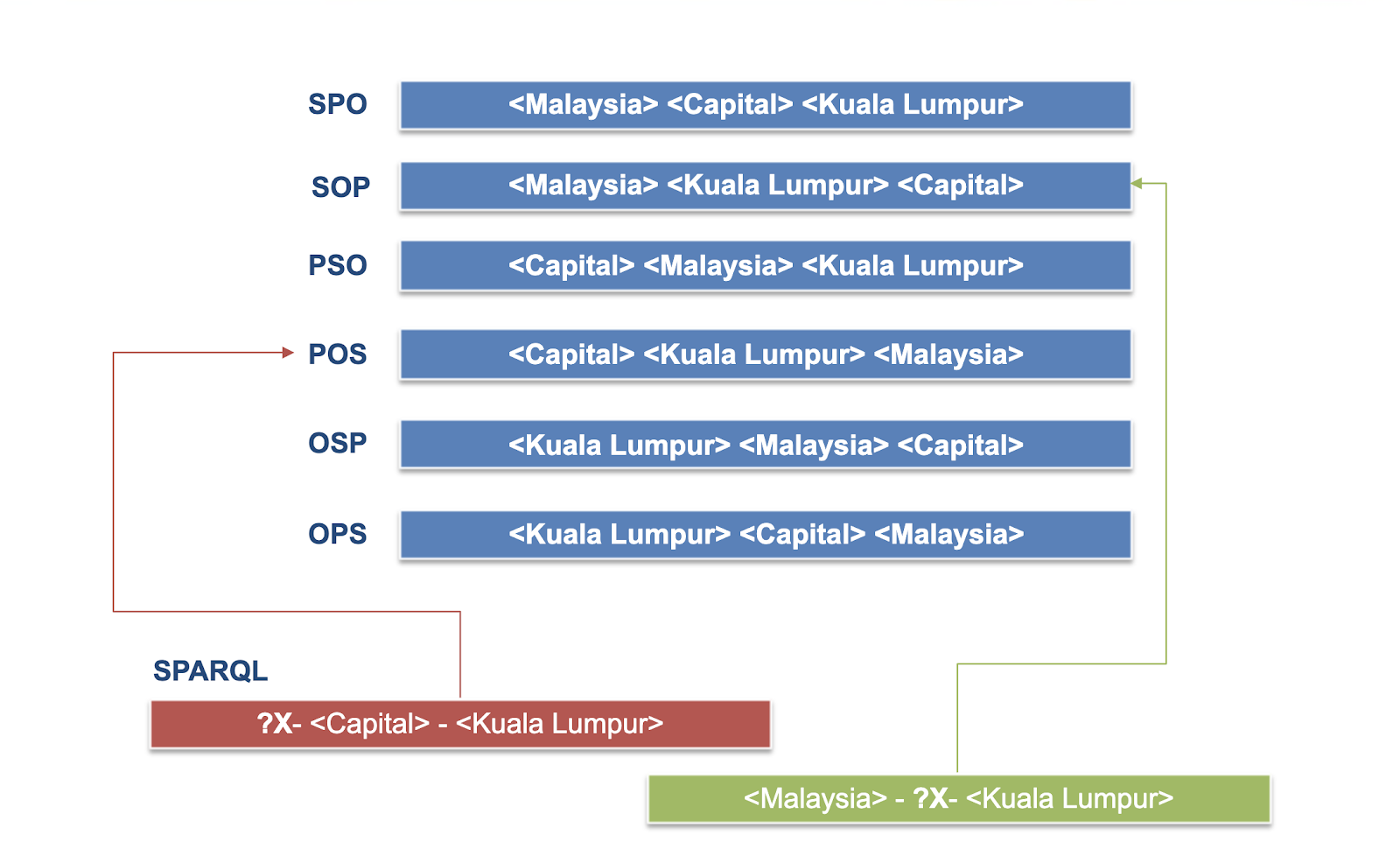
Где, например, SPO - это триплет в изначальной форме, а POS - запись вида predicate object subject.
Шесть таких индексов позволяют вычислять простейшие graph patterns с одной переменной, например
?x <capital> <Kuala Lumpur>
или
<Malaysia> ?x <Kuala Lumpur>
Для хранения триплетов используются B+ деревья, где в листьях содержатся не абсолютные значения индексированных компонентов, а относительные delta:
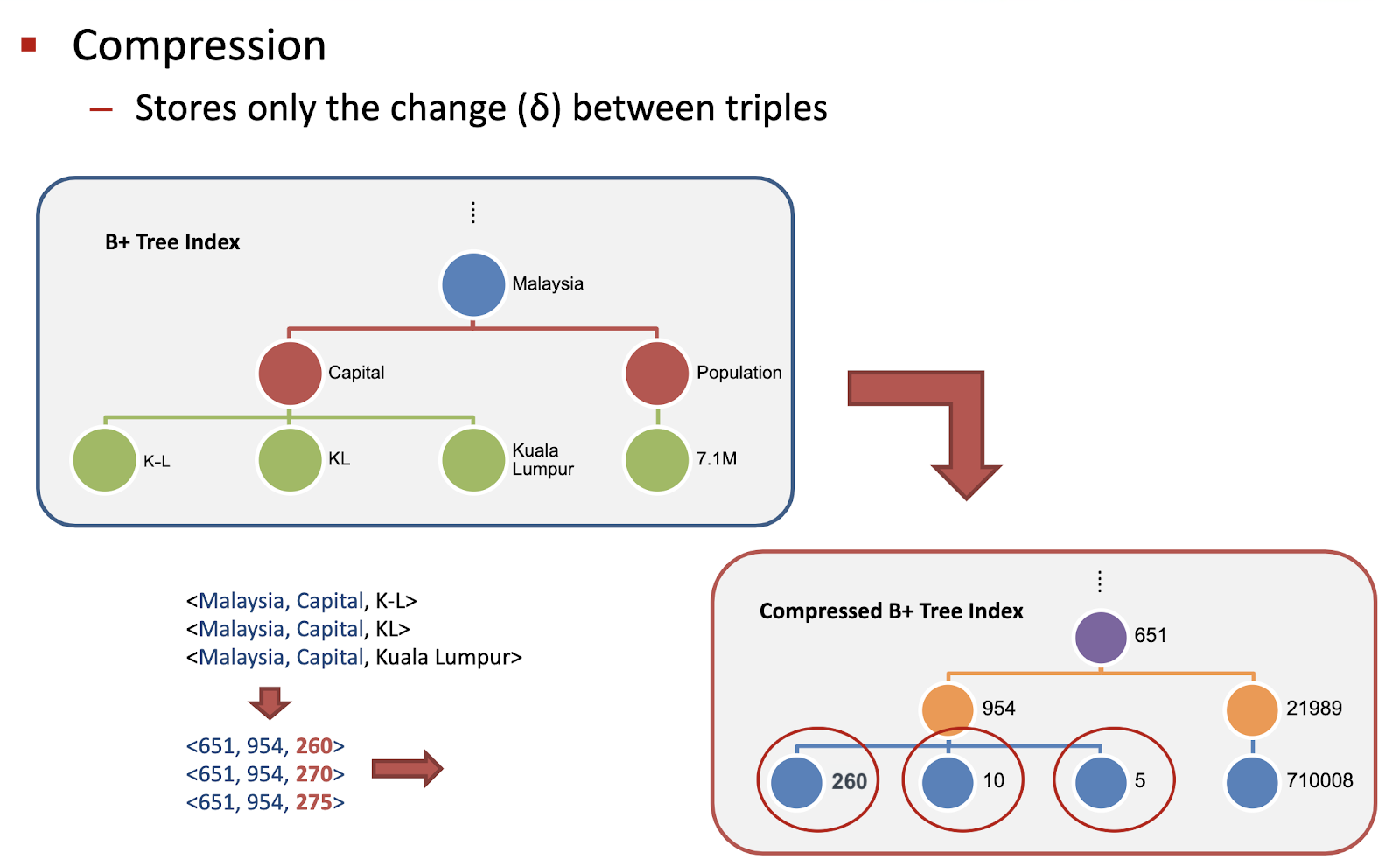
Т.е. вместо хранения индексов 260, 270, 275 листья будут содержать 260, 10, 5 (как попарные дельты с предыдущим значением). Это позволяет записать индексы меньшим числом байтов.
Two-value indexes
Еще одним типом индекса являются Two-valued indexes - счетчики всех встречающихся комбинаций SP, SO, PS, PO, OS, OP. Они полезны, если недостающий элемент тройки далее не используется. Например, если Malaysia и Kuala Lumpur как subject и object (SO) встречаются четыре раза, то в этом индексе значение этой пары будет равно четырем. Такой индекс можно использовать взамен полного индекса, если predicate используется лишь в одном шаблоне подграфа и в то же время отсутствует в возвращаемых переменных:

One-value indexes
Наконец, последним типом индексов являются счетчики формата (value, count) количества использований каждого уникального субъекта, предиката и объекта ( S, P, O), соответственно .
Три типа индексов позволяют RDF-3X отвечать практически на все BGP, предусмотренные SPARQL 1.0.
Отметим, однако, что RDF-3X это read-only хранилище, то есть оно не позволяет обновлять уже индексированный граф. Для поддержки записи (и, соответственно, операций INSERT и DELETE) в современных графовых БД используются Log-structured merge trees (LSM-trees).
LSM Trees
LSM-деревья имеют константную сложность операций вставки и удаления. Хорошее описание работы LSM приведено в серии статей [5] на Medium. Как правило, LSM-деревья оперируют блоками данных (data block), находящимися в оперативной памяти (memory blocks) и на диске (disk block). Блоками могут быть и B+-деревья из предыдущей главы. Чтение блоков может производиться как из оперативной памяти, так и с диска, но запись производится только через оперативную память.
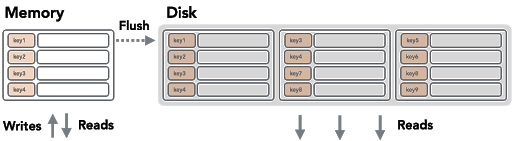 Источник: Medium
Источник: Medium
Для экономии места наши data blocks должны оптимизироваться операцией merge. Например, при объединении двух блоков (на иллюстрации ниже) запись Alex обновится на ту, что пришла позже (timestamp 200), а запись John удалится, т.к. пришла команда DELETE. Записи Sid и Nancy перейдут в новый блок без изменений.
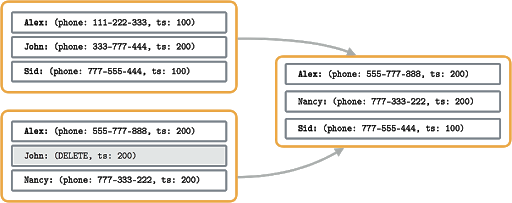
LSM-деревья используются в RocksDB и Stardog.
HDT
Одним из самых эффективных по сжатию и скорости индексирования RDF графов является механизм HDT (Header Dictionary Triple) [6].
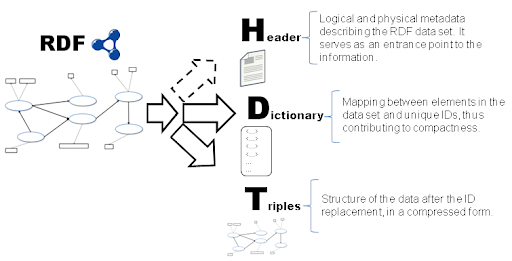
HDT представляет собой бинарный формат представления триплетов, обеспечивающий высокую степень сжатия. HDT содержит три основные части описания графа.
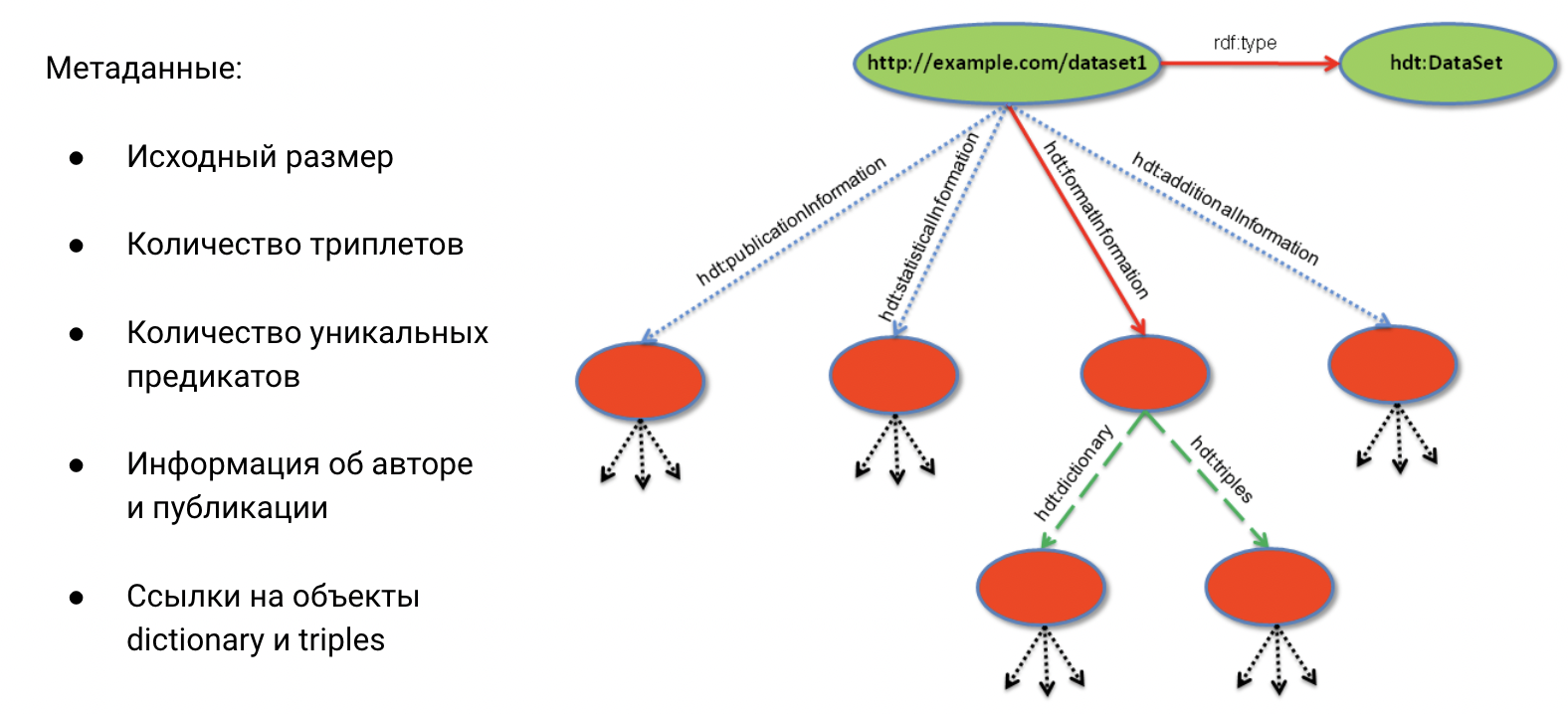
Header - метаданные о графе, в т.ч. исходный размер, количество триплетов, уникальных предикатов, информация об авторе и времени публикации исходного графа, а также ссылки на объекты Dictionary и Triples
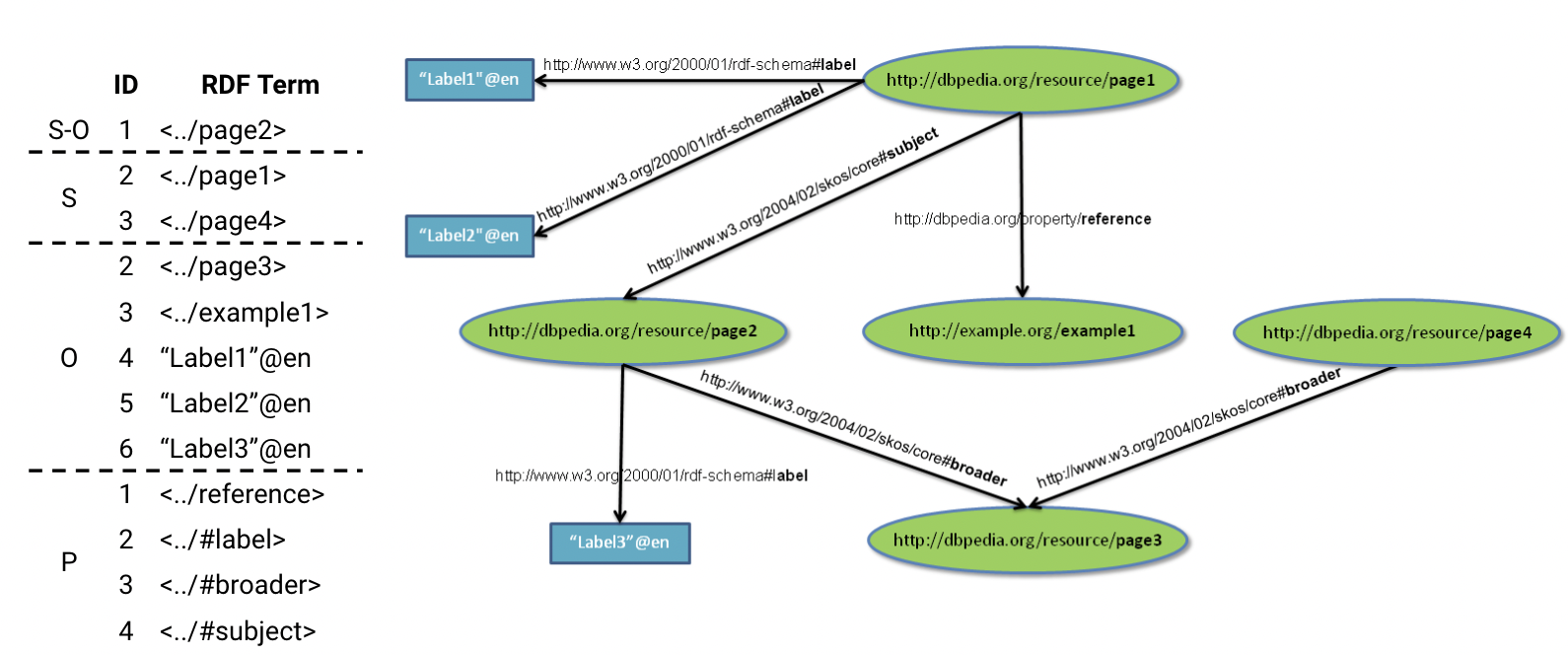
Dictionary - словарь (ассоциативный массив), назначающий уникальные идентификаторы всем уникальным субъектам, предикатам и объектам, причем идентификаторы зависят от структуры графа. Сперва ID назначаются сущностям, которые находятся в графе на месте и субъекта, и объекта (S-O), затем остальным уникальным субьъектам S и объектам O. Наконец, и предикатам назначаются ID:
Triples - кодирование триплетов с помощью битовых карт и вейвлетных деревьев для сжатия и сокращения объема итогового HDT-файла. На этом этапе граф сортируется в одном порядке (например, SPO - subject, predicate, object), и граф преобразуется в лес, где каждое дерево - уникальный субъект. В каждом дереве на втором уровне - отсортированные предикаты, связанные с этим субъектом в исходном графе, и на третьем уровне - отсортированные объекты.
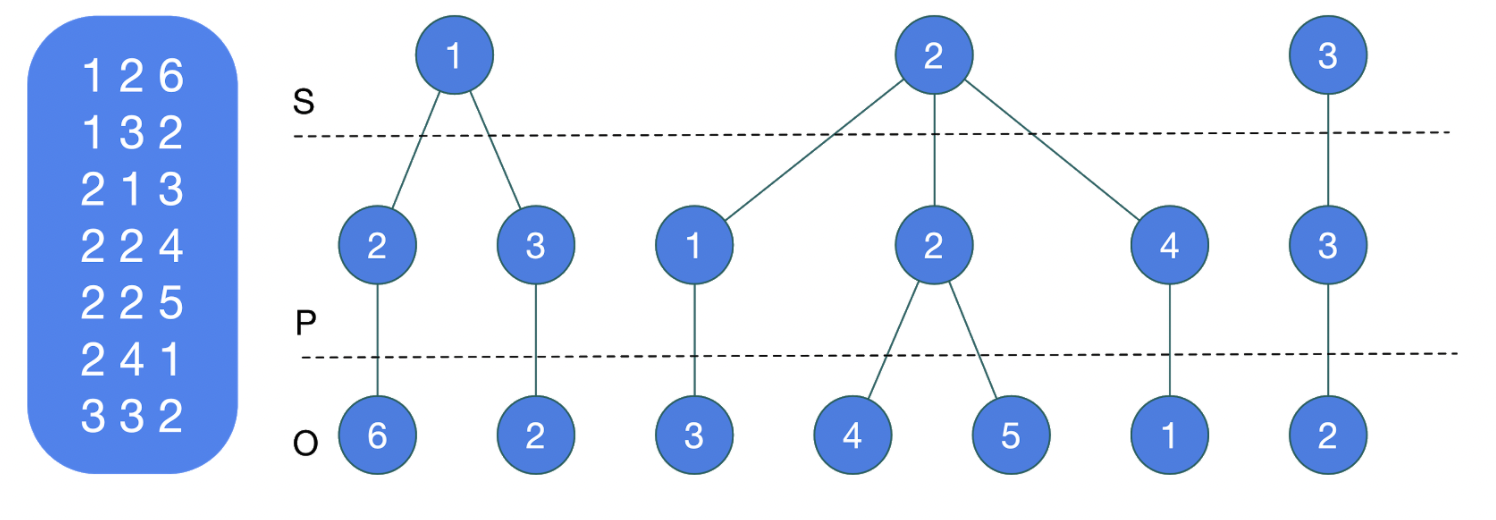
Затем предикаты и объекты помещаются в лист и кодируются битовой картой, показывающей принадлежность предиката или объекта материнскому узлу дерева.
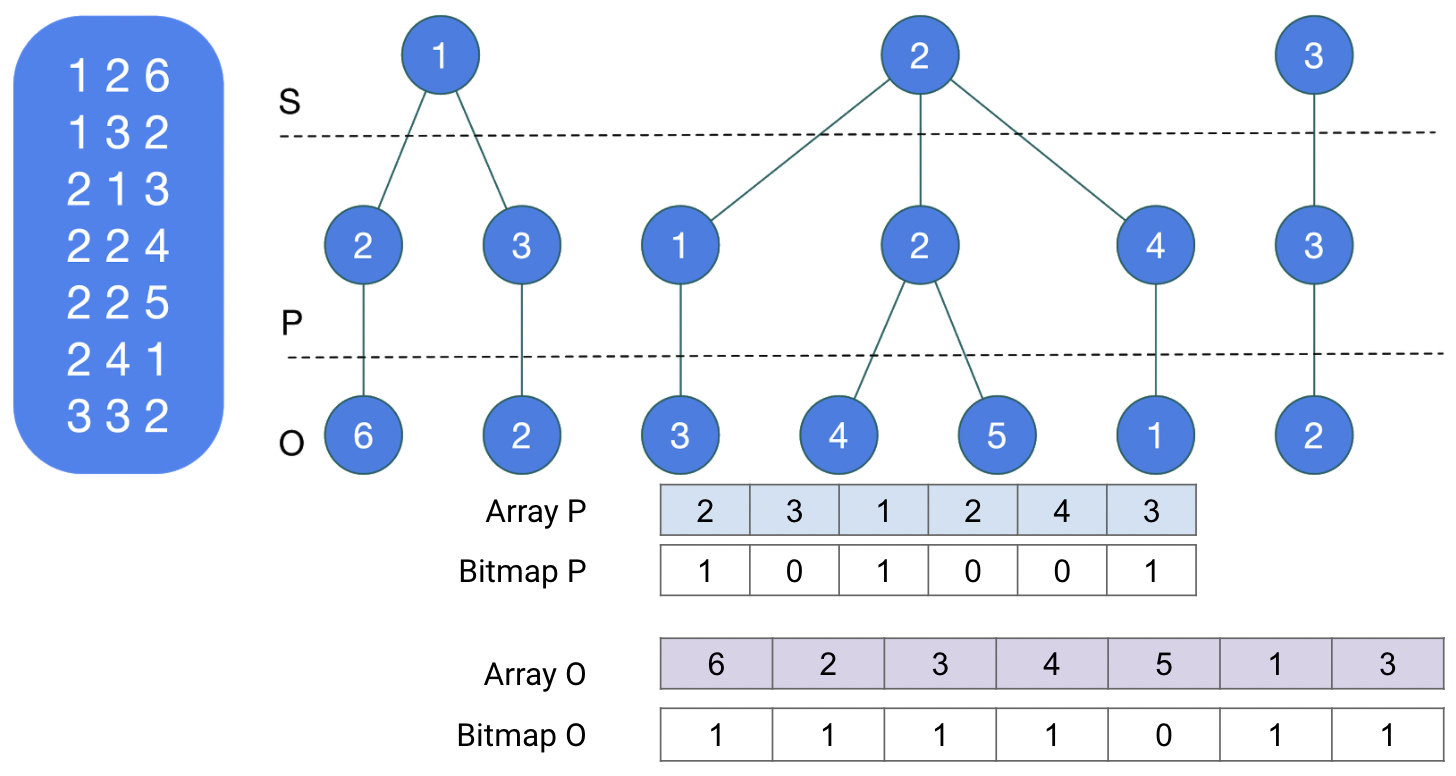
Заметим, однако, что такое кодирование оптимизировано для простых SPARQL запросов формата spo, sp?, s??, ???, но поиск от заданного предиката или объекта сложен. Поэтому в процессе обработки HDT датасета строятся еще несколько индексов по модели вейвлет-деревьев (Wavelet tree), чтобы поддерживать все варианты построения BGP в SPARQL:

Для вейвлет-деревьев определено несколько операций:
access(position)- получить значение на определеннойpositionrank(entry, position)- посчитать, сколько раз значениеentryвстречается вплоть до позицииpositionвключительноselect(entry, i)- найти позицию, на которой значениеentryвстркчается вi-ый раз
Наконец, для обработки запросов с константными objects строится O-P index:
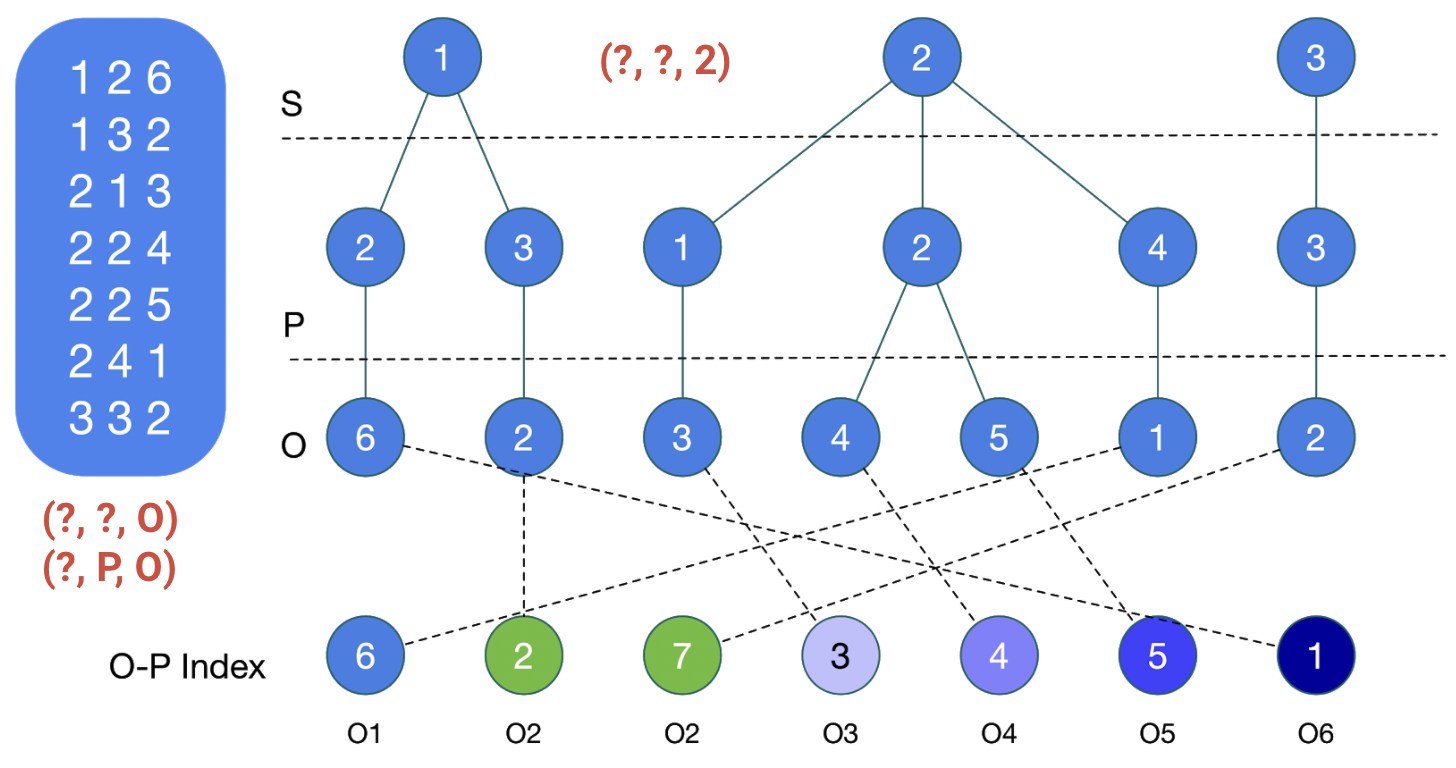
В этом индексе указывается, на каких позициях во всех деревьях встречается конкретный object ID. Например, объект с ID 1 впервые встречается на позиции 6, поэтому O1: 6, а объект с индексом 2 дважды - на позициях 2 и 7, поэтому O2: [2, 7].
В итоге, bitmaps, wavelet trees и O-P index позволяют обрабатывать практически все возможные BGP.
На основе формата HDT строится Linked Data Fragments - новый подход к публикации RDF-датасетов в сети, способный транслировать SPARQL-запросы во внутренний формат и производить ответы на запросы кумулятивно - т.е. выводить результаты по мере их появления, а не все сразу. Отметим, что некоторая часть обработки запроса ложится в том числе и на SPARQL-клиент в отличие от классический точек доступа SPARQL, где все вычисления производятся на стороне сервера и RDF-хранилища. Коллекция датасетов [7] постоянно пополняется и содержит графы разных размеров - от всей Wikidata до меньших WordNet или Semantic Web Dog Food.
LPG
В отличие от RDF графов, в качестве модели представления в таких СУБД используются Labeled Property Graphs (LPG). Хорошее описание различий представлено в статье [8]
 Источник: [8]
Источник: [8]
В модели LPG и сущности, и связи между ними могут иметь произвольные атрибуты (properties). Например, на рисунке выше некоторая сущность Company имеет предикат :HAS_CEO со значением Employee. При этом, предикат :HAS_CEO инстанцируется с атрибутом start_date: 2008-01-20, что детализирует связь между двумя узлами, а значение Employee имеет набор атрибутов name: Amy Peters, date_of_birth: 1984-03-01, employee_ID: 1.
LPG является надмножеством RDF в возможности задания атрибутов предикатам наравне с узлами графа. В чем отличия?
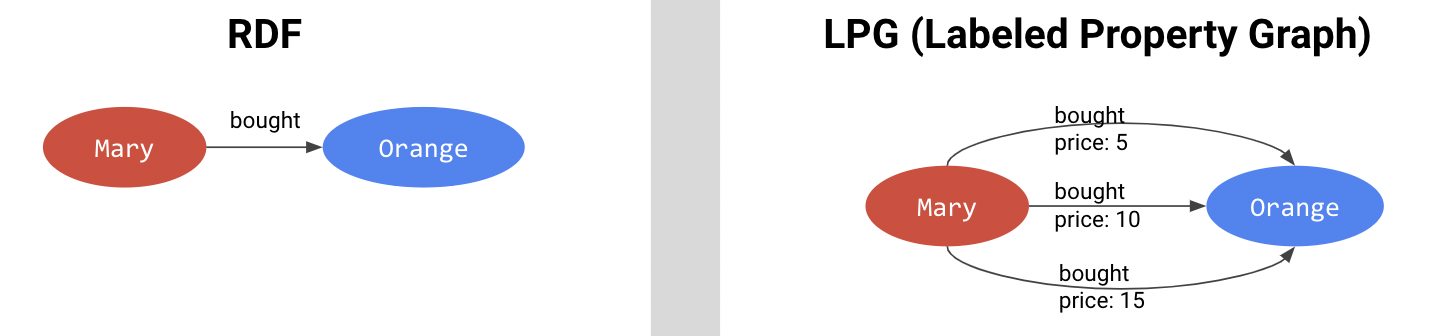
- Как мы уже знаем, в RDF предикаты могут иметь только специальные логические атрибуты из онтологий RDFS или OWL, что с одной стороны придает RDF возможности логического вывода, недоступные LPG, а с другой не позволяет делать экземпляры предикатов с конкретными свойствами для конкретных сущностей (например,
“Маша дружит с Дашей с 1 сентября 2008 года”). Как обходной путь в RDF существует понятие реификации (Reification), которое мы рассмотрим в следующих лекциях, но наиболее простой и мощный способ по-прежнему предоставляют модели LPG. - В RDF нет понятия уникальных предикатов, поэтому моделирование одинаковых предикатов между двумя сущностями в общем случае нетривиально. Например, моделируя факт
“Маша купила три апельсина”с помощью предиката:boughtмодель LPG позволит создать три экземпляра предиката:boughtмеждуМашаиАпельсин, а в RDF все три будут сведены к одному общему предикату:bought. - В LPG нет понятия именованных графов (named graphs), которые позволяют объединять RDF графы по некоторому контексту.
Cypher
Ярким представителем графовых СУБД по модели LPG является Neo4j. Neo4j продвигает собственный язык Cypher как стандарт запросов графовых хранилищ. Почти все конструкты Cypher могут быть представлены и в SPARQL, например:
# Cypher
MATCH (s:Person)
WHERE s.name = “John”
RETURN s;
SELECT ?s WHERE {
?s a :Person;
:name “John” }
MATCH (s:Person)-[:knows]-(friend)
WHERE s.name = “John”
RETURN s, friend ;
SELECT ?s ?friend WHERE {
?s a :Person;
:name “John” ;
:knows ?friend }
Однако стандартный компонент Cypher для запросов по атрибутам предикатов может быть выражен только в нестандартизированном расширении SPARQL* с использованием реификации:
# Cypher
MATCH (s:Person)-[:knows {since:2001}] -> (js)
RETURN s;
# SPARQL*
SELECT ?s WHERE {
<<?s :knows :js>>
:since 2001 }
Существуют языки, абстрагирующиеся от конкретной имплементации и позволяющие транслировать запрос и в Cypher, и в SPARQL. Такими языками являются, например, Gremlin и GraphQL.
Gremlin разработан в рамках проекта Apache Tinkerpop [9] как язык обхода графов, полный по Тьюрингу и работающий в среде JVM. Gremlin использует функциональную парадигму и способен работать с императивными и декларативными стилями запросов. В рамках Tinkerpop Gremlin позиционируется как уровень абстракции между графовыми СУБД (Neo4j, GraphDB) и аналитическими платформами (Spark, Hadoop).
В настоящий момент Gremlin поддерживается среди прочих в Neo4j, Amazon Neptune, GraphDB, Stardog, Spark, Apache Giraph. Пример Gremlin traversal:
public class GremlinTinkerPopExample {
public void run(String name, String property) {
Graph graph = GraphFactory.open(...);
GraphTraversalSource g = graph.traversal();
double avg = g.V().has("name",name).
out("knows").out("created").
values(property).mean().next();
System.out.println("Average rating: " + avg);
}
}
GraphQL, разработанный Facebook, позиционируется скорее как замена REST API для сервисов, основанных на графовых БД, нежели как чистый язык запросов. Однако, его выразительность позволяет транслировать запросы в Cypher и SPARQL. Neo4j поддерживает трансляцию запросов GraphQL в Cypher и результатов по обратной схеме, тогда как Stardog [10] / GraphDB [11] транслируют запросы в SPARQL, а результаты из SPARQL в GraphQL.
Пусть задан простой граф:
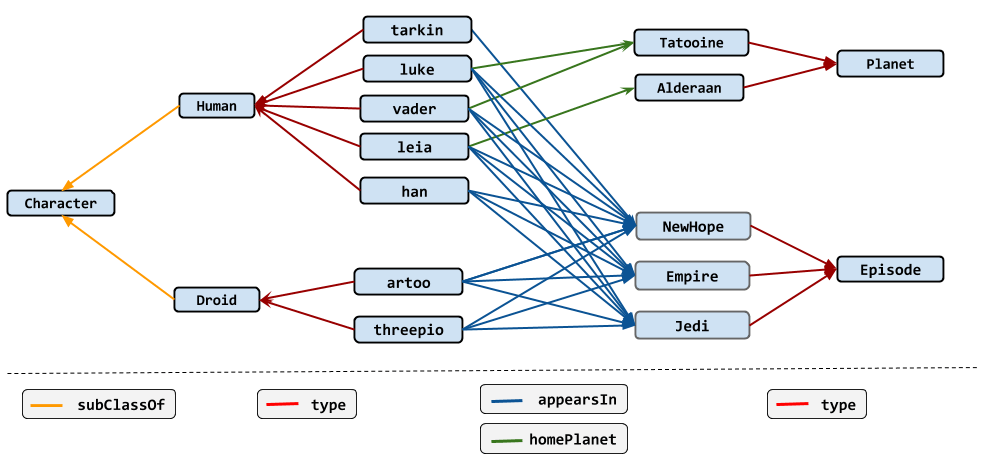 )
)
Тогда GraphQL запрос:
{
Human {
name
}
}
Вернет все имена сущностей Human:
{ “data”: [
{
“name”: “tarkin”
},
{
“name”: “luke”
},
{
“name”: “vader”
},
{
“name”: “leia”
},
{
“name”: “han”
}
]}
Домашнее задание
Попрактикуйтесь составлять SPARQL-запросы к DBpedia endpoint по адресу https://dbpedia.org/sparql
Префиксы, которые вам могут понадобиться: инстансы dbr:, классы и предикаты из онтологии dbo:
- Получите все предикаты и объекты сущности
dbr:Albert_Einstein - Найдите город рождения (
dbo:birthPlace) (классdbo:Town) и дату рождения (dbo:birthDate) Эйнштейна - Найдите все места работы Эйнштейна (
dbo:institution), которые при этом являются инстансом классаdbo:University - Найдите, за что известны (
dbo:knownFor) одновременноdbr:Albert_Einsteinиdbr:Satyendra_Nath_Bose. А за что известны одновременноdbr:Albert_Einsteinиdbr:Kip_Thorne? - Найдите русский лейбл (
rdfs:label) сущностиdbr:Albert_Einstein - Найдите, сколько наград получил (
dbo:award) Эйнштейн - Cколько наград получил (
dbo:award) Эйнштейн, в названии которых естьMedal? - На каких физиков (
dbo:academicDiscipline dbr:Physics) повлиял (dbo:influencedBy) Эйнштейн? - Найдите русскоязычный лейбл явления, за которое известны (
dbo:knownFor) Эйнштейн и Александр Столетов (dbr:Aleksandr_Stoletov) - Используйте property path, чтобы найти, в каких странах (
dbo:country) расположены места работы (dbo:institution) Эйнштейна? - Используйте property path, чтобы найти все
rdf:type(всех уровней) мест работы (dbo:institution) Эйнштейна? - Какие награды получил Эйнштейн, но не получал
dbr:Richard_Feynman?
Использованные материалы и ссылки:
[0] Adrian Bielefeldt, Julius Gonsior, Markus Krötzsch. Practical Linked Data Access via SPARQL: The Case of Wikidata. LDOW 2018
[1] https://www.w3.org/TR/rdf-sparql-query/#evaluation
[2] https://www.w3.org/TR/sparql11-query/
[3] David C. Faye, Olivier Curé, Guillaume Blin. A survey of RDF storage approaches, 2012, ARIMA Journal
[4] Neumann, T., Weikum, G. The RDF-3X engine for scalable management of RDF data. The VLDB Journal 19, 91–113 (2010). https://doi.org/10.1007/s00778-009-0165-y
[5] https://medium.com/databasss/ on-disk-io-part-3-lsm-trees-8b2da218496f
[6] http://www.rdfhdt.org
[7] https://www.rdfhdt.org/datasets/
[8] https://neo4j.com/blog/rdf-triple-store-vs-labeled-property-graph-difference/
[9] http://tinkerpop.apache.org/gremlin.html
[10] https://docs.stardog.com/query-stardog/graphql#graphql
[11] https://platform.ontotext.com/soml/queries.html